Este es el manual oficial de usuario de DBRECOVER for Oracle. Utilice el índice de la izquierda para saltar a un escenario de recuperación concreto; para una visión integral, léalo de principio a fin.
Visión general
DBRECOVER for Oracle es un software de recuperación de desastres de datos Oracle de nivel empresarial. Permite extraer y recuperar datos directamente desde los datafiles de bases de datos Oracle, desde Oracle 8i hasta 21c, sin necesidad de ejecutar consultas SQL contra una instancia Oracle en marcha. DBRECOVER está desarrollado en Java, no requiere instalación adicional y puede utilizarse directamente tras descargar y descomprimir el paquete.
DBRECOVER ofrece una interfaz gráfica intuitiva, cómoda y sencilla de manejar. El usuario no necesita aprender un conjunto de comandos aparte ni comprender las estructuras internas de almacenamiento de Oracle; el Recovery Wizard (asistente de recuperación) guía todo el flujo de recuperación.
¿Por qué elegir DBRECOVER?
Una pregunta habitual es si la recuperación mediante backups con Oracle Recovery Manager (RMAN) basta y por qué hace falta DBRECOVER. La respuesta proviene de los escenarios reales de recuperación.
Con el rápido crecimiento de los sistemas de TI empresariales, la capacidad de datos aumenta de forma exponencial. Los DBA de Oracle se enfrentan con frecuencia a problemas como que el almacenamiento en disco no tenga capacidad suficiente para guardar backups completos, o que el tiempo medio de restauración desde cinta exceda con creces lo previsto.
«El backup lo es todo en una base de datos» es una máxima que todo DBA tiene presente. Pero la realidad raras veces colabora: capacidad de backup insuficiente, dispositivos de almacenamiento que no llegan a tiempo y backups que resultan inservibles cuando llega el momento de restaurar son situaciones muy habituales.
Para resolver estos dilemas habituales de recuperación de datos en el mundo real, DBRECOVER aprovecha al máximo su conocimiento de la estructura interna de datos de Oracle, del proceso de arranque del kernel y de otros principios internos del motor. Puede afrontar situaciones en las que la base de datos no abre con normalidad por pérdida del tablespace SYSTEM, operaciones erróneas sobre las tablas del diccionario de datos de Oracle o inconsistencias del diccionario provocadas por cortes de corriente, incluso sin backups disponibles. También permite remediar errores humanos como truncar, eliminar o droppear tablas de negocio, y recuperar los datos con menos pasos manuales.
Incluso personal no DBA que apenas lleva unos días con Oracle puede manejar DBRECOVER con facilidad, gracias a su sencilla instalación y a su interfaz totalmente gráfica. Quien ejecuta la recuperación no necesita una experiencia profunda en recuperación de bases de datos, ni aprender procedimientos de línea de comandos, ni conocer la estructura interna de almacenamiento. Bastan unos cuantos clics para recuperar datos con muy pocos pasos manuales. DBRECOVER rompe la barrera de que solo unos pocos profesionales puedan acometer tareas de recuperación de bases de datos, acorta enormemente el tiempo entre el fallo y la recuperación completa, y reduce el coste total de la recuperación de datos en la empresa.
Los datos que DBRECOVER puede recuperar admiten dos modalidades. El método tradicional de extracción saca los datos del datafile y los vuelca a un fichero plano de texto, que después se importa en la base de datos con herramientas como SQLLDR. Es un método simple e intuitivo, pero exige un espacio equivalente al doble de la capacidad actual de los datos: uno para el fichero plano y otro para la carga en base de datos; además, dobla el tiempo, ya que primero hay que extraer los datos originales del datafile y luego importarlos en la nueva base de datos.
Recomendamos encarecidamente otro método: el innovador Data Bridge (puente de datos) de DBRECOVER. Este método carga los datos extraídos directamente en una base de datos nueva o disponible a través de DBRECOVER, evitando que pasen por almacenamiento intermedio. Frente al método tradicional, ahorra de forma efectiva el espacio y el tiempo necesarios para la recuperación.
La tecnología ASM (Automatic Storage Management) de Oracle es adoptada por cada vez más empresas. Frente a los sistemas de ficheros tradicionales, las bases de datos sobre ASM ofrecen alto rendimiento, soporte para clústeres y una gestión cómoda. Sin embargo, el problema de ASM es que su estructura de almacenamiento es demasiado compleja y difícil de entender para el usuario corriente. Si la estructura interna de un Disk Group en ASM resulta dañada y no consigue hacer MOUNT, los datos importantes del usuario quedan «encerrados» en esa «caja negra» que es ASM. En esa situación se suele necesitar a ingenieros senior de Oracle, conocedores de la estructura interna de ASM, que se desplacen para reparar manualmente la estructura interna; contratar el servicio in situ de Oracle suele ser caro y lento para los usuarios habituales.
Como los desarrolladores de DBRECOVER conocen a fondo la estructura interna de datos de Oracle ASM, DBRECOVER incorpora una función de recuperación específica para ASM.
Actualmente, las funciones de recuperación de datos sobre ASM que soporta DBRECOVER incluyen:
Aunque el Disk Group no pueda hacer MOUNT con normalidad, DBRECOVER puede leer directamente los metadatos disponibles en el disco ASM y, basándose en ellos, copiar los archivos ASM del Disk Group.
Aunque el Disk Group no pueda hacer MOUNT con normalidad, DBRECOVER puede leer directamente los datafiles que residen en ASM y extraer datos de ellos, tanto con el método tradicional como con el método Data Bridge.
Introducción a DBRECOVER for Oracle
DBRECOVER for Oracle está desarrollado en JAVA, lo que garantiza que pueda ejecutarse de forma multiplataforma: tanto en Unix (AIX, Solaris, HP-UX) como en Linux (Red Hat, Oracle Linux, SUSE) e incluso en Windows.
Plataformas de sistema operativo soportadas por DBRECOVER:
| Plataforma | Soporte |
| Windows | YES |
| AIX | YES |
| Solaris Sparc/X86 | YES |
| Linux x86/64 | YES |
| HPUX | YES |
| MacOS | YES |
Versiones de base de datos soportadas actualmente por DBRECOVER: 8i ~ 21C
DBRECOVER incluye el entorno JAVA necesario para su ejecución, por lo que en Windows y Linux no es preciso instalar JAVA por separado.
En Windows, haga doble clic para ejecutar start_dbrecover_windows_local_java.bat
En Linux, ejecute: sh start_dbrecover_linux_local_java.sh
En entornos tipo UNIX como AIX, HP-UX o Solaris, el usuario debe instalar por su cuenta el entorno JAVA 8.
Juegos de caracteres de base de datos soportados por DBRECOVER:
| Idioma | Juego de caracteres | Codificación |
| Chino | ZHS16GBK | GBK |
| Chino | ZHS16DBCS | CP935 |
| Chino | ZHT16BIG5 | BIG5 |
| Chino | ZHT16DBCS | CP937 |
| Chino | ZHT16HKSCS | CP950 |
| Chino | ZHS16CGB231280 | GB2312 |
| Chino | ZHS32GB18030 | GB18030 |
| Japonés | JA16SJIS | SJIS |
| Japonés | JA16EUC | EUC_JP |
| Japonés | JA16DBCS | CP939 |
| Coreano | KO16MSWIN949 | MS649 |
| Coreano | KO16KSC5601 | EUC_KR |
| Coreano | KO16DBCS | CP933 |
| Francés | WE8MSWIN1252 | CP1252 |
| Francés | WE8ISO8859P15 | ISO8859_15 |
| Francés | WE8PC850 | CP850 |
| Francés | WE8EBCDIC1148 | CP1148 |
| Francés | WE8ISO8859P1 | ISO8859_1 |
| Francés | WE8PC863 | CP863 |
| Francés | WE8EBCDIC1047 | CP1047 |
| Francés | WE8EBCDIC1147 | CP1147 |
| Alemán | WE8MSWIN1252 | CP1252 |
| Alemán | WE8ISO8859P15 | ISO8859_15 |
| Alemán | WE8PC850 | CP850 |
| Alemán | WE8EBCDIC1141 | CP1141 |
| Alemán | WE8ISO8859P1 | ISO8859_1 |
| Alemán | WE8EBCDIC1148 | CP1148 |
| Italiano | WE8MSWIN1252 | CP1252 |
| Italiano | WE8ISO8859P15 | ISO8859_15 |
| Italiano | WE8PC850 | CP850 |
| Italiano | WE8EBCDIC1144 | CP1144 |
| Tailandés | TH8TISASCII | CP874 |
| Tailandés | TH8TISEBCDIC | TIS620 |
| Árabe | AR8MSWIN1256 | CP1256 |
| Árabe | AR8ISO8859P6 | ISO8859_6 |
| Árabe | AR8ADOS720 | CP864 |
| Español | WE8MSWIN1252 | CP1252 |
| Español | WE8ISO8859P1 | ISO8859_1 |
| Español | WE8PC850 | CP850 |
| Español | WE8EBCDIC1047 | CP1047 |
| Portugués | WE8MSWIN1252 | CP1252 |
| Portugués | WE8ISO8859P1 | ISO8859_1 |
| Portugués | WE8PC850 | CP850 |
| Portugués | WE8EBCDIC1047 | CP1047 |
| Portugués | WE8ISO8859P15 | ISO8859_15 |
| Portugués | WE8PC860 | CP860 |
Tipos de almacenamiento de tabla soportados por DBRECOVER:
| Tipo de almacenamiento de tabla | Soportado |
| Tabla Cluster | SÍ |
| Index-Organized Table, particionada o no particionada | NO |
| Heap-Organized Table, particionada o no particionada | SÍ |
| Heap-Organized Table con Basic Compression | NO |
| Heap-Organized Table con Advanced Compression | NO |
| Heap-Organized Table con Hybrid Columnar Compression | NO |
| Heap-Organized Table con cifrado | NO |
| Tabla con columnas virtuales | NO |
| Filas encadenadas, filas migradas | SÍ |
Nota: en columnas virtuales y columnas con valor por defecto optimizado de 11g, la extracción de datos suele completarse sin errores, pero se pierden los campos correspondientes. Ambas son funcionalidades posteriores a 11g y no se usan habitualmente.
Tipos de datos de columna soportados por DBRECOVER:
| Tipo de dato | Soportado |
| BFILE | No |
| Binary XML | No |
| BINARY_DOUBLE | Sí |
| BINARY_FLOAT | Sí |
| BLOB | Sí |
| CHAR | Sí |
| CLOB and NCLOB | Sí |
| Colecciones (incluidos VARRAY y tablas anidadas) | No |
| Date | Sí |
| INTERVAL DAY TO SECOND | Sí |
| INTERVAL YEAR TO MONTH | Sí |
| LOB almacenados como SecureFiles | Sí |
| LONG | Sí |
| LONG RAW | Sí |
| Tipos de datos multimedia (incluidos Spatial, Image y Oracle Text) | No |
| NCHAR | Sí |
| Number | Sí |
| NVARCHAR2 | Sí |
| RAW | Sí |
| ROWID, UROWID | Sí |
| TIMESTAMP | Sí |
| TIMESTAMP WITH LOCAL TIMEZONE | Sí |
| TIMESTAMP WITH TIMEZONE | Sí |
| Tipos definidos por el usuario | No |
| VARCHAR2 and VARCHAR | Sí |
| XMLType almacenado como CLOB | No |
| XMLType almacenado como Object Relational | No |
Soporte de ASM en DBRECOVER:
| Funcionalidad | Soportado |
| Extracción directa de datos desde ASM, sin necesidad de copiar al sistema de ficheros | SÍ |
| Copia de datafiles desde ASM | SÍ |
Instalación y arranque de DBRECOVER
DBRECOVER es un software portátil basado en Java y no requiere un proceso de instalación específico. Tras descomprimir el paquete ZIP descargado, ya se puede utilizar para recuperar datos.
Para arrancar DBRECOVER:
- En Windows: haga doble clic para ejecutar
start_dbrecover_windows_local_java.bat
- En Linux: puede usar el software en local con interfaz gráfica, o bien con herramientas remotas como Xmanager o VNC. Antes de lanzarlo, asegúrese de poder abrir el reloj gráfico
xclock. Después, en el directorio donde descomprimió el software, ejecute:sh start_dbrecover_linux_local_java.sh
En entornos AIX, HP-UX o Solaris, DBRECOVER se puede usar en local con interfaz gráfica o mediante herramientas remotas como Xmanager o VNC. Pasos para arrancar DBRECOVER:
- Compruebe que está instalado el entorno Java 8 correspondiente a la plataforma. Para verificarlo, use el comando
java -version.
- Asegúrese de poder abrir el reloj gráfico
xclock.
- En el directorio donde descomprimió el software, ejecute:
sh start_dbrecover.sh
Registrar la licencia de DBRECOVER
DBRECOVER for Oracle es software comercial. Existe una edición comunitaria de DBRECOVER para que los usuarios puedan probarlo y aprender a manejarlo.
Actualmente solo se ofrece un tipo de licencia: la licencia empresarial. Consulte la página de precios de DBRECOVER for Oracle para más información sobre la compra.
Tras obtener la License Key, el usuario puede registrarla por sí mismo dentro del software. El procedimiento concreto es:
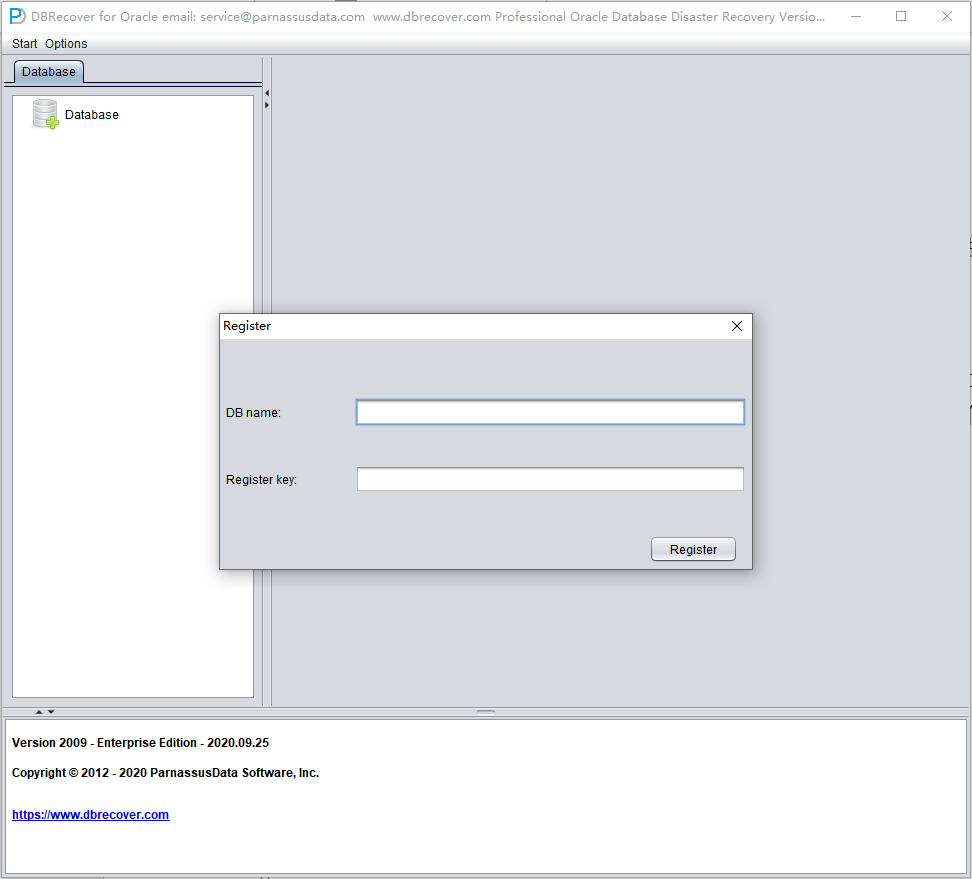
Para registrar la licencia de DBRECOVER, siga estos pasos:
- En la barra de menú vaya a «Help» y seleccione «Register».
- Con la información que recibió tras la compra, introduzca su DB NAME y la clave, y pulse el botón «Register».
- Una vez completado el registro, cada vez que reinicie DBRECOVER se comprobará automáticamente la información de licencia y no tendrá que volver a registrarse.
Puede consultar la información del registro correcto en «Help» => «About».
Uso de DBRECOVER en escenarios de recuperación de Oracle
Escenario de recuperación 1: Corrupción de datafile de Oracle que impide abrir la base de datos
La base de datos de producción de la empresa A funciona todo el año en modo no archivado; de vez en cuando se hacen backups lógicos con EXP, pero nunca backups físicos. Un día, tras un corte eléctrico y un reinicio del servidor, la base de datos no puede abrirse con normalidad. Al revisarla se constata que el tablespace SYSTEM está gravemente dañado. En este punto se puede usar DBRECOVER para transferir rápidamente los datos de la base de datos dañada a una nueva base de datos recién creada, restaurando con rapidez las operaciones del negocio.
En escenarios similares, si se encuentra con errores como ORA-01194, ORA-01110, ORA-01033, ORA-01115, ORA-00368, ORA-00600 kcbzib_kcrsds_1, ORA-00333, ORA-01113, ORA-01122, ORA-27027, etc., que impiden abrir la base de datos, puede intentar recuperar los datos siguiendo los pasos descritos en este escenario.
Los pasos resumidos son los siguientes:
- Usar dbca para crear una nueva base de datos ORACLE, asegurándose de que el juego de caracteres coincide con el de la base de datos dañada.
- Crear los usuarios y tablespaces correspondientes en la nueva base de datos; se recomienda otorgar temporalmente el rol DBA a estos usuarios.
- Arrancar el listener (LISTENER) y asegurarse de que el servicio de la base de datos está registrado en él.
- Arrancar DBRECOVER en modo diccionario y cargar todos los datafiles de la base de datos dañada original.
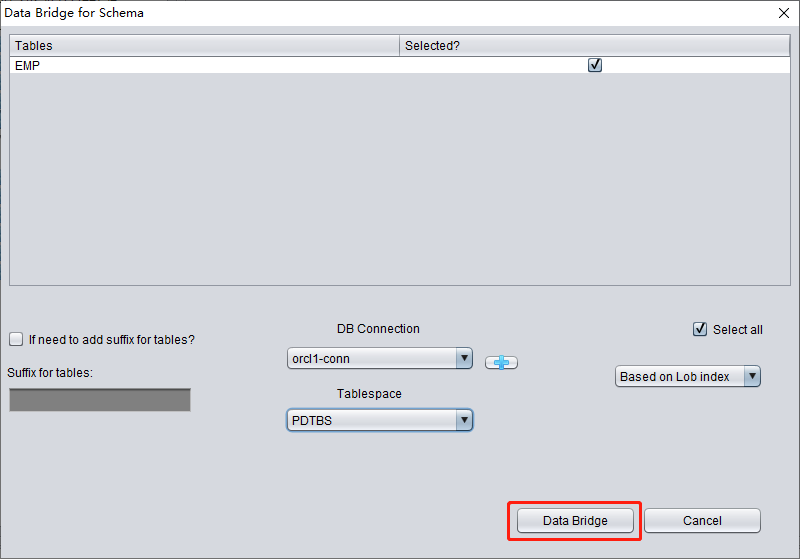
- En DBRECOVER, seleccionar el usuario que se quiere recuperar, hacer clic derecho y elegir Data Bridge (puente de datos).
- En la interfaz de Data Bridge, pulsar el icono más para añadir la información de conexión a la nueva base de datos (Connection).
- Pulsar Data Bridge para iniciar la transferencia y esperar a que todas las tablas del SCHEMA pasen al SCHEMA destino de la base de datos destino.
- Seleccionar el SCHEMA correspondiente, hacer clic derecho y elegir la función EXPORTDDL (exportar DDL); seleccionar los tipos de objeto que se quieren recuperar y pulsar EXPORT.
- A partir del fichero DDL SQL generado por EXPORTDDL, ejecutar manualmente las sentencias en el SCHEMA destino de la base de datos destino.
Nota de recuperación: arranque el listener (LISTENER) y compruebe que el servicio de la base de datos queda registrado en él.
C:\Users\testenv>lsnrctl status
LSNRCTL for 64-bit Windows: Version 11.2.0.1.0 - Production on 12-MAY-2023 10:01:48
Copyright (c) 1991, 2010, Oracle. All rights reserved.
Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=DESKTOP-testenv)(PORT=1521)))
STATUS of the LISTENER
-----------------------
Alias LISTENER
Version TNSLSNR for 64-bit Windows: Version 11.2.0.1.0 - Production
Start Date 12-MAY-2023 10:00:49
Uptime 0 days 0 hr. 0 min. 59 sec
Trace Level off
Security ON: Local OS Authentication
SNMP OFF
Listener Parameter File D:\app\testenv\product\11.2.0\dbhome_2\network\admin\listener.ora
Listener Log File d:\app\testenv\diag\tnslsnr\DESKTOP-testenv\listener\alert\log.xml
Listening Endpoints Summary...
(DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=DESKTOP-testenv)(PORT=1521)))
(DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(PIPENAME=\\.\pipe\EXTPROC1521ipc)))
Services Summary...
Service "CLRExtProc" has 1 instance(s).
Instance "CLRExtProc", status UNKNOWN, has 1 handler(s) for this service...
Service "ORCL1XDB" has 1 instance(s).
Instance "orcl1", status READY, has 1 handler(s) for this service...
Service "ORCLXDB" has 1 instance(s).
Instance "orcl", status READY, has 1 handler(s) for this service...
Service "orcl" has 1 instance(s).
Instance "orcl", status READY, has 1 handler(s) for this service...
Service "orcl1" has 1 instance(s).
Instance "orcl1", status READY, has 1 handler(s) for this service...
The command completed successfully
Nota de recuperación: cree los usuarios y tablespaces correspondientes en la nueva base de datos; se recomienda otorgar temporalmente el rol DBA a estos usuarios.
set ORACLE_SID=ORCL1
sqlplus / as sysdba
SQL> create user pd identified by oracle;
User created.
SQL> grant dba to pd;
Grant succeeded.
SQL> create tablespace pdtbs datafile size 500M autoextend on next 100M;
Tablespace created.
SQL> alter user pd default tablespace pdtbs;
User altered.
Arranque DBRECOVER y seleccione Tools => Recovery Wizard.
Pulse Next.
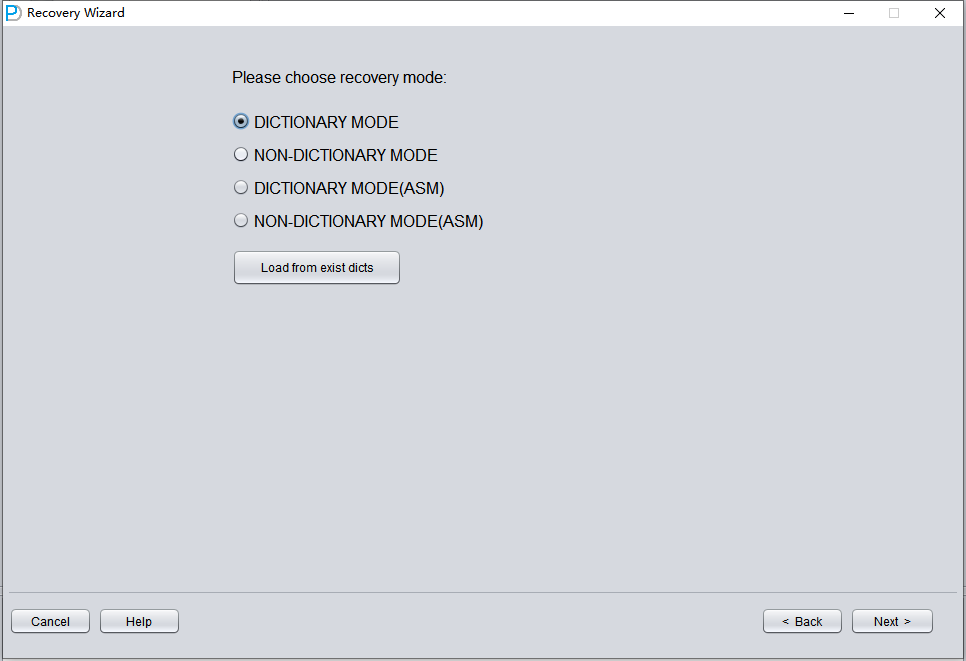
El siguiente paso es elegir el orden de bytes ENDIAN correcto. Los datafiles de Oracle utilizan distintos formatos endian según la plataforma de sistema operativo.
Endian es la forma en que se almacenan en memoria los tipos de datos multibyte; determina el orden de los bytes. Existen dos variantes: Little y Big. En Little Endian se almacena primero el «extremo pequeño», es decir, el primer byte es el más significativo según una convención; en Big Endian se almacena primero el «extremo grande», es decir, el primer byte es el menos significativo.
En las bases de datos Oracle, el formato endian viene determinado por el entorno en el que se ejecuta. Ese formato indica a qué entornos se puede trasladar la base de datos. No es posible mover una base de datos por los métodos habituales entre entornos con distinto endian: por ejemplo, no se puede transferir una base de datos con Data Guard desde un sistema Little Endian a uno Big Endian.
Puede consultar el formato endian actual de su base de datos con la siguiente consulta:
El resultado le indicará el formato endian de la base de datos actual.
El formato Big Endian se da en plataformas como IBM AIX, Apple Mac OS, HP-UX (64 bits), HP-UX IA (64 bits), IBM Power Based Linux, IBM zSeries Based Linux y Solaris OE (32 y 64 bits).
El formato Little Endian se da en plataformas como Linux x86 64 bits, Apple Mac OS (x86-64), HP IA Open VMS, HP Open VMS, HP Tru64 UNIX, Linux IA (32 bits), Linux IA (64 bits), Microsoft Windows IA (32 bits), Microsoft Windows IA (64 bits), Microsoft Windows x86 64 bits y Solaris Operating System (x86 y x86-64).
La correspondencia entre orden de bytes y plataforma es la siguiente:
| Plataforma | Endian |
| Solaris[tm] OE (32-bit) | Big |
| Solaris[tm] OE (64-bit) | Big |
| Microsoft Windows IA (32-bit) | Little |
| Linux IA (32-bit) | Little |
| AIX-Based Systems (64-bit) | Big |
| HP-UX (64-bit) | Big |
| HP Tru64 UNIX | Little |
| HP-UX IA (64-bit) | Big |
| Linux IA (64-bit) | Little |
| HP Open VMS | Little |
| Microsoft Windows IA (64-bit) | Little |
| IBM zSeries Based Linux | Big |
| Linux x86 64-bit | Little |
| Apple Mac OS | Big |
| Microsoft Windows x86 64-bit | Little |
| Solaris Operating System (x86) | Little |
| IBM Power Based Linux | Big |
| HP IA Open VMS | Little |
| Solaris Operating System (x86-64) | Little |
| Apple Mac OS (x86-64) | Little |
Solo hay que tener en cuenta que las plataformas más habituales, Windows y Linux, son ambas Little Endian, por lo que no hace falta configurar nada y se puede mantener el valor por defecto.
En plataformas Unix de gama media, como sistemas basados en AIX (64 bits) y HP-UX (64 bits), se usa Big Endian, por lo que en esos casos hay que seleccionar Big Endian.
Tenga en cuenta: si sus datafiles se generaron en AIX (es decir, Big Endian) y los copió a un servidor Windows por comodidad para recuperarlos con DBRECOVER, debe seguir indicando su formato original Big Endian.
En este caso, como estamos recuperando ficheros de base de datos Oracle de la plataforma Linux x86-64, escogemos Little Endian.
Pulse Next.
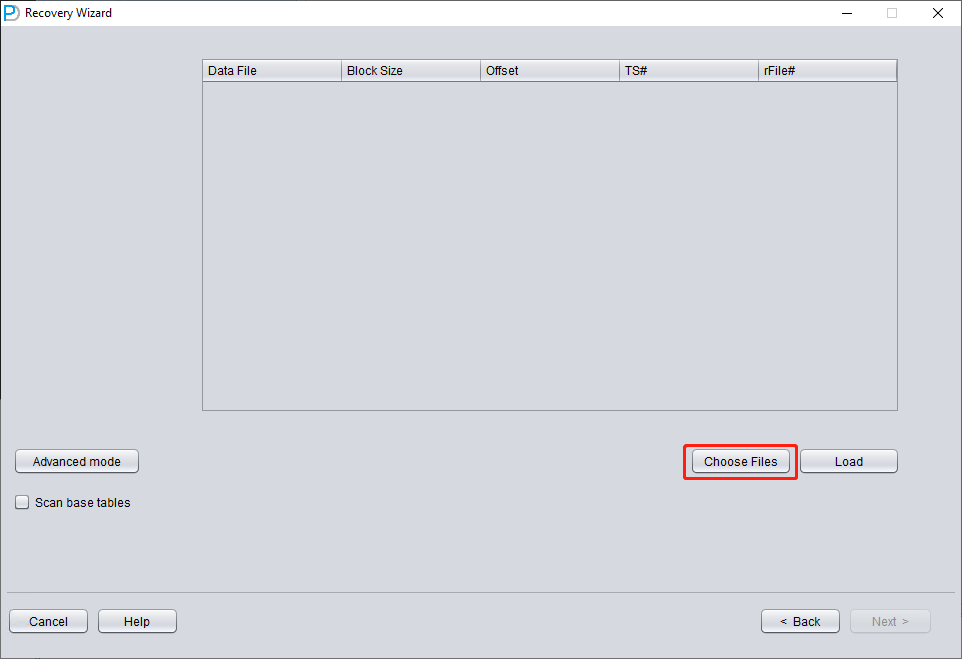
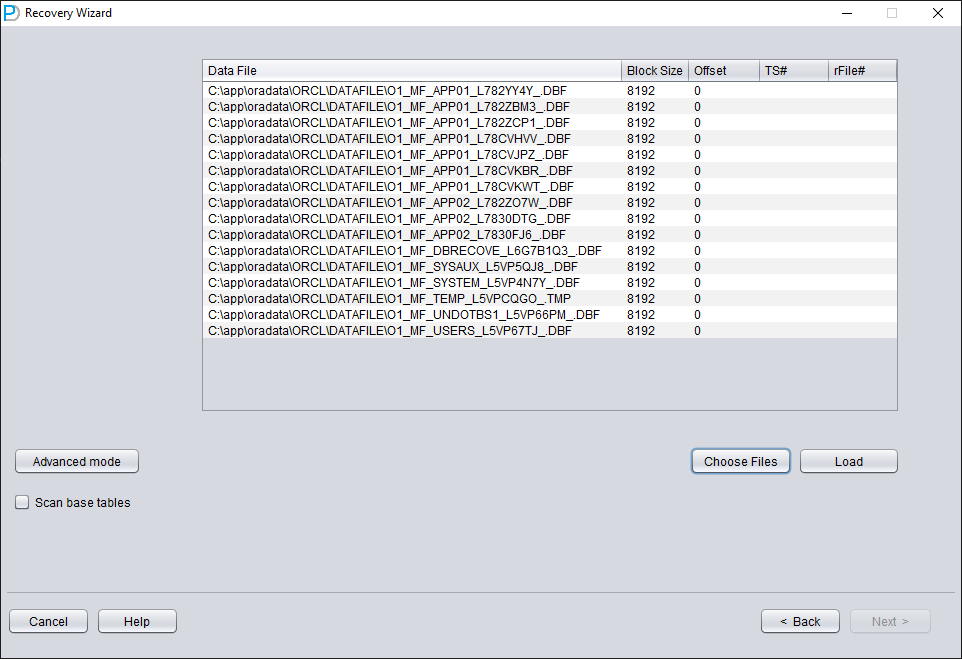
Pulse «Choose Files». En general, si la base de datos no es muy grande, recomendamos seleccionar todos sus datafiles. Si la base de datos es muy grande y sabe en qué datafiles están sus tablas, puede seleccionar únicamente los datafiles del tablespace SYSTEM (obligatorio) más los datafiles que contienen los datos.
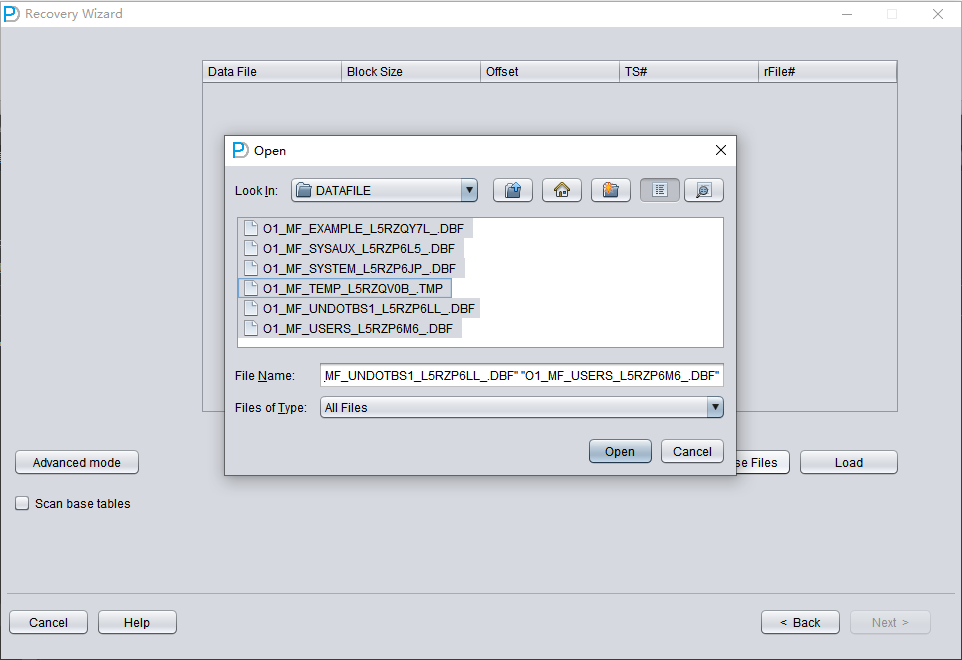
Tenga en cuenta que la ventana de selección admite las combinaciones de teclado Ctrl + A y Mayús.
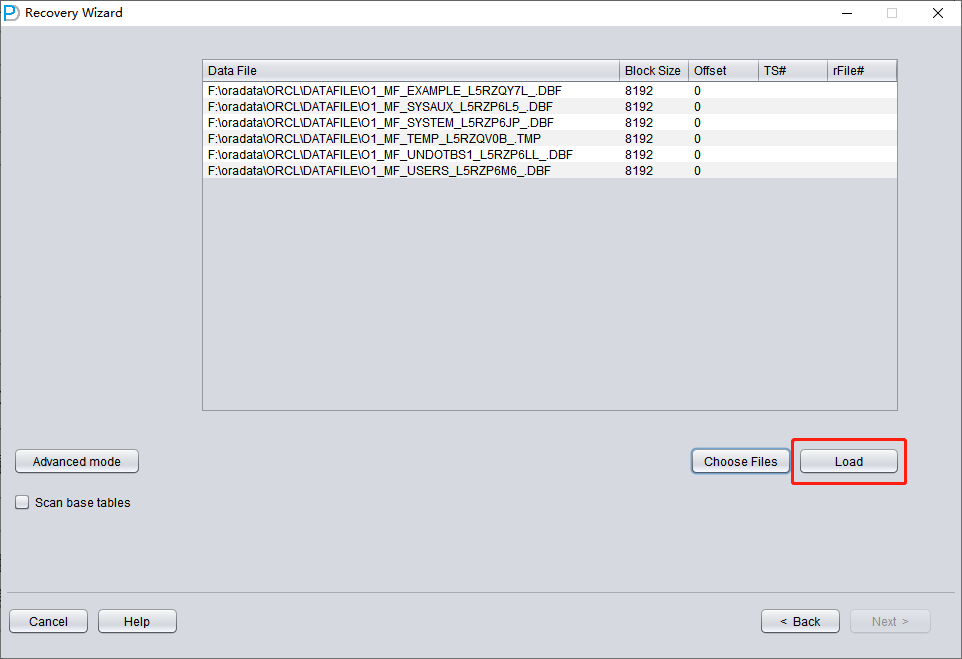
Nota: tras añadir todos los datafiles, si no comprende el resto de parámetros de esta pantalla, mantenga los valores por defecto y no los modifique.
A continuación hay que especificar el Block Size del datafile indicado, es decir, el tamaño del bloque ORACLE. Aquí se puede ajustar según la situación real. Por ejemplo, si su DB_BLOCK_SIZE es de 8K pero algún tablespace declara 16K como tamaño de bloque, solo hace falta cambiar el BLOCK_SIZE de los datafiles que no sean de 8k.
Si utiliza un sistema de ficheros convencional, no hace falta especificar OFFSET aquí. El parámetro OFFSET está pensado sobre todo para escenarios en los que los datafiles se almacenan en raw devices. Por ejemplo, en AIX, si se usa el LV de un VG normal como datafile, existe un OFFSET de 4k que sí hay que indicar aquí.
Si está usando datafiles sobre raw device y desconoce el OFFSET, puede comprobarlo con la herramienta dbfsize incluida en $ORACLE_HOME/bin. El siguiente ejemplo muestra un raw device que no tiene OFFSET de 4K:
$ dbfsize /dev/lv_control_01
Database file: /dev/lv_control_01
Database file type: raw device without 4K starting offset
Database file size: 334 16384 byte blocks
Como en este escenario todos los datafiles tienen un BLOCK SIZE de 8K y residen en un sistema de ficheros, ninguno tiene OFFSET; pulse «Load».
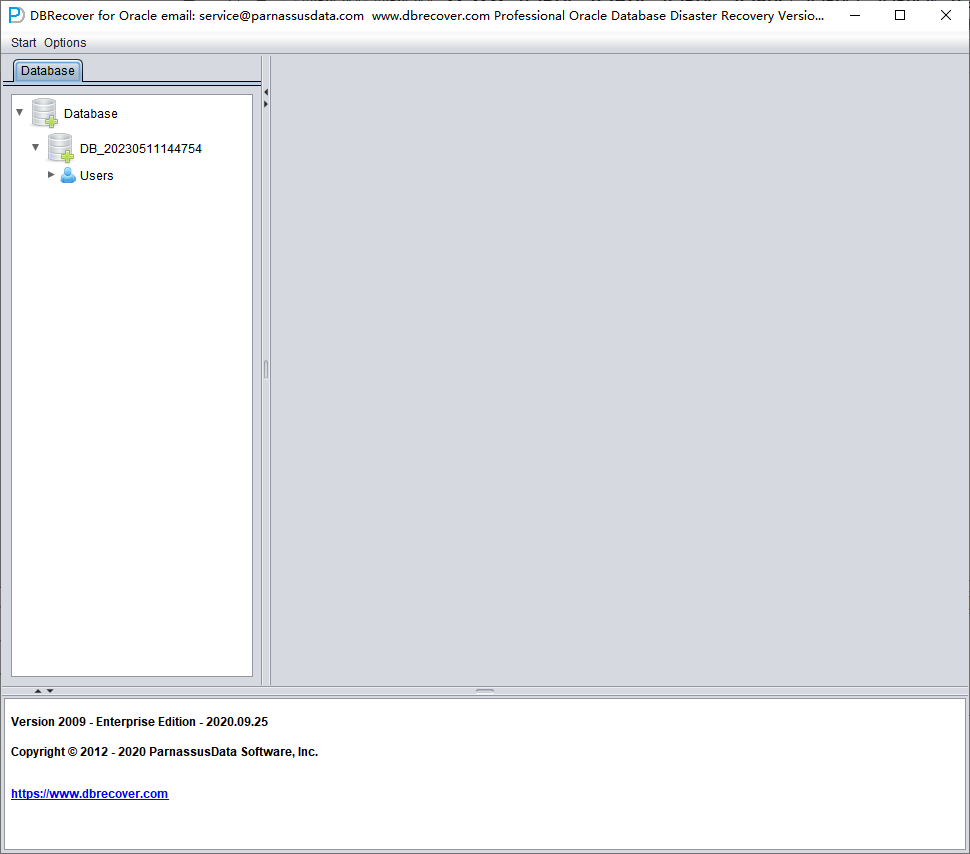
En la fase de Load, DBRECOVER lee la información del diccionario de datos de ORACLE desde el tablespace SYSTEM y construye un diccionario de datos en su Derby integrado. Eso le permite analizar después distintos datos de la base de datos ORACLE.
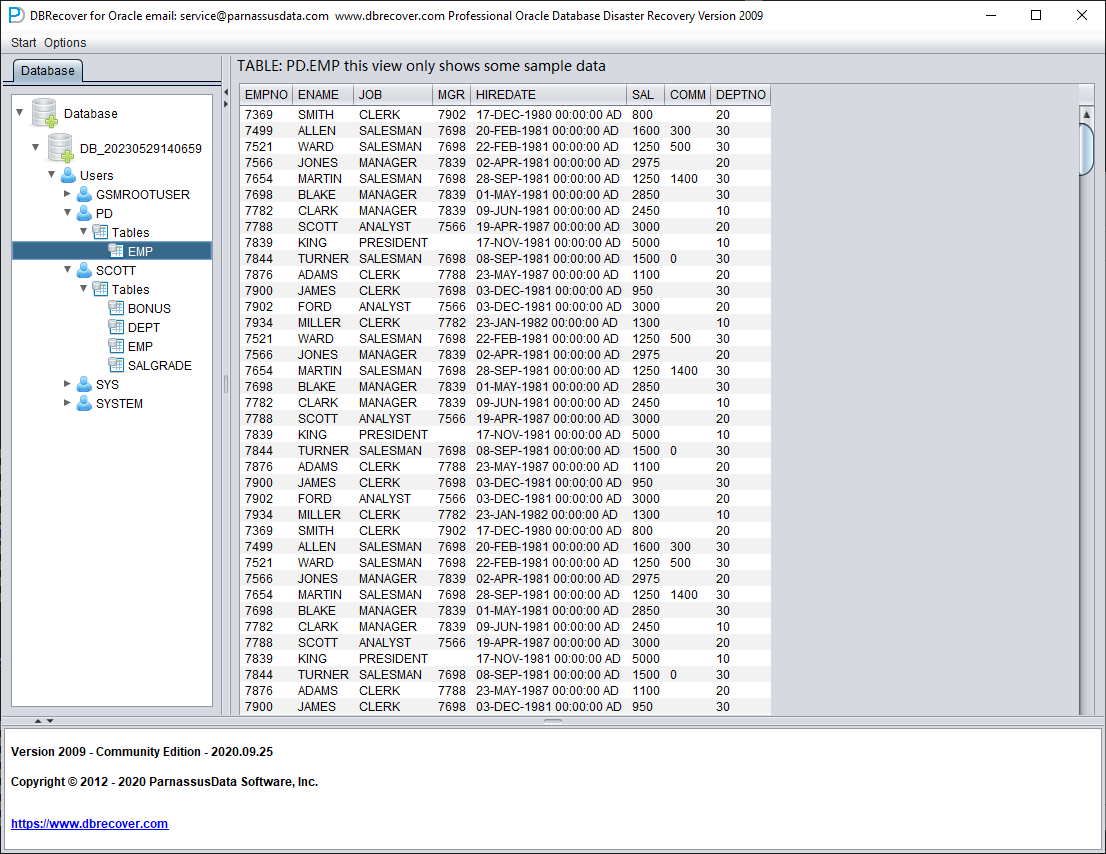
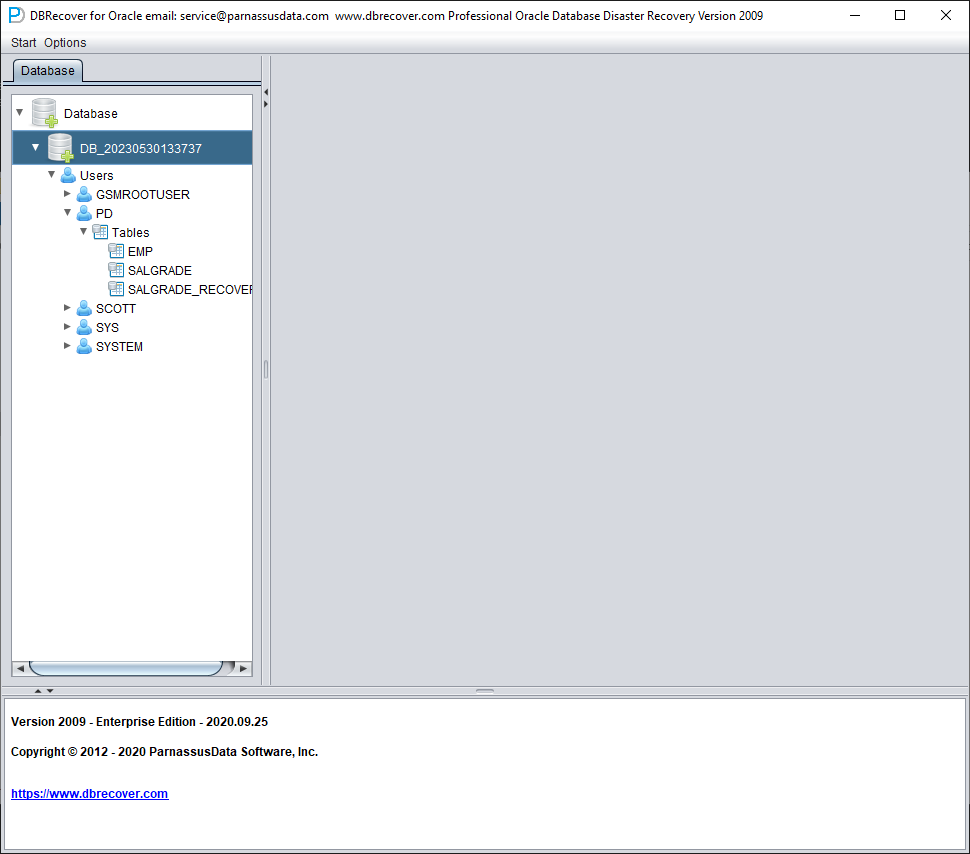
Una vez completado el Load, la interfaz de DBRECOVER muestra a la izquierda un árbol agrupado por usuarios de la base de datos:
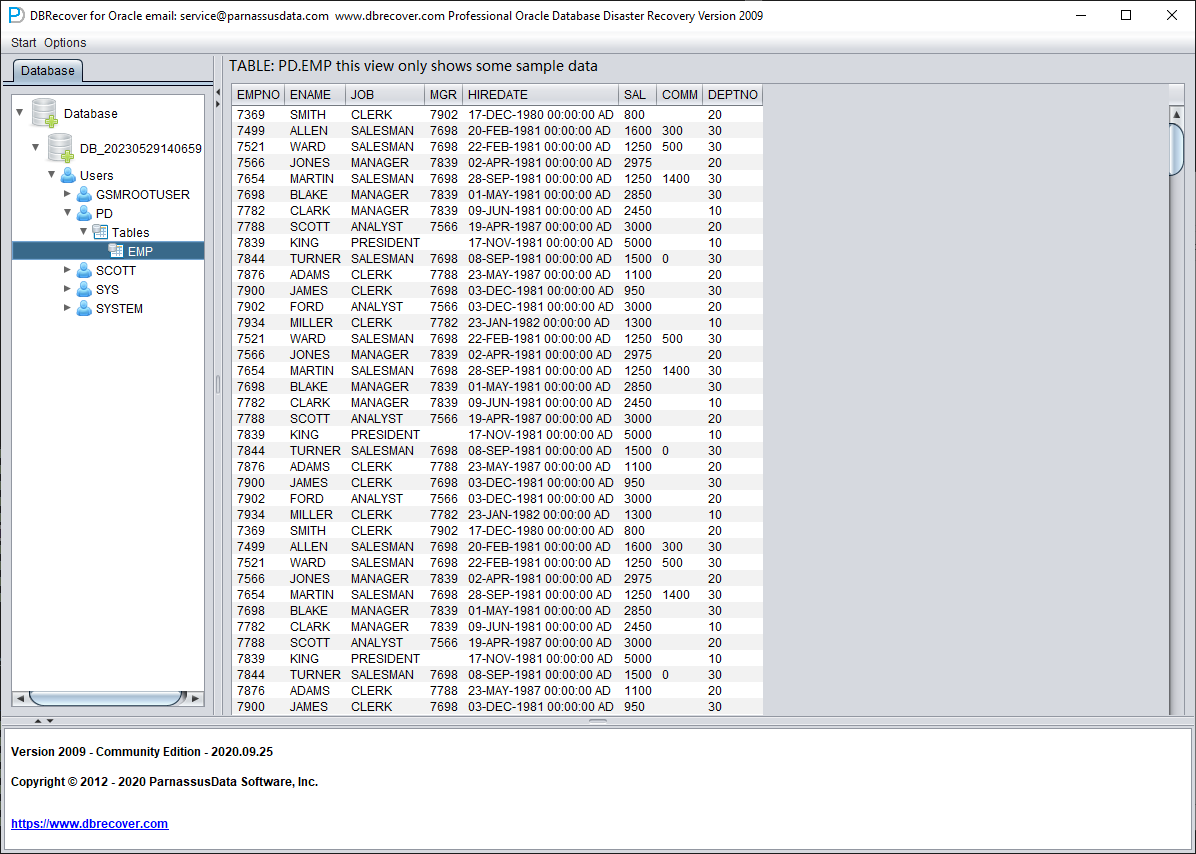
Seleccione una tabla que quiera recuperar y haga doble clic para visualizar sus datos:
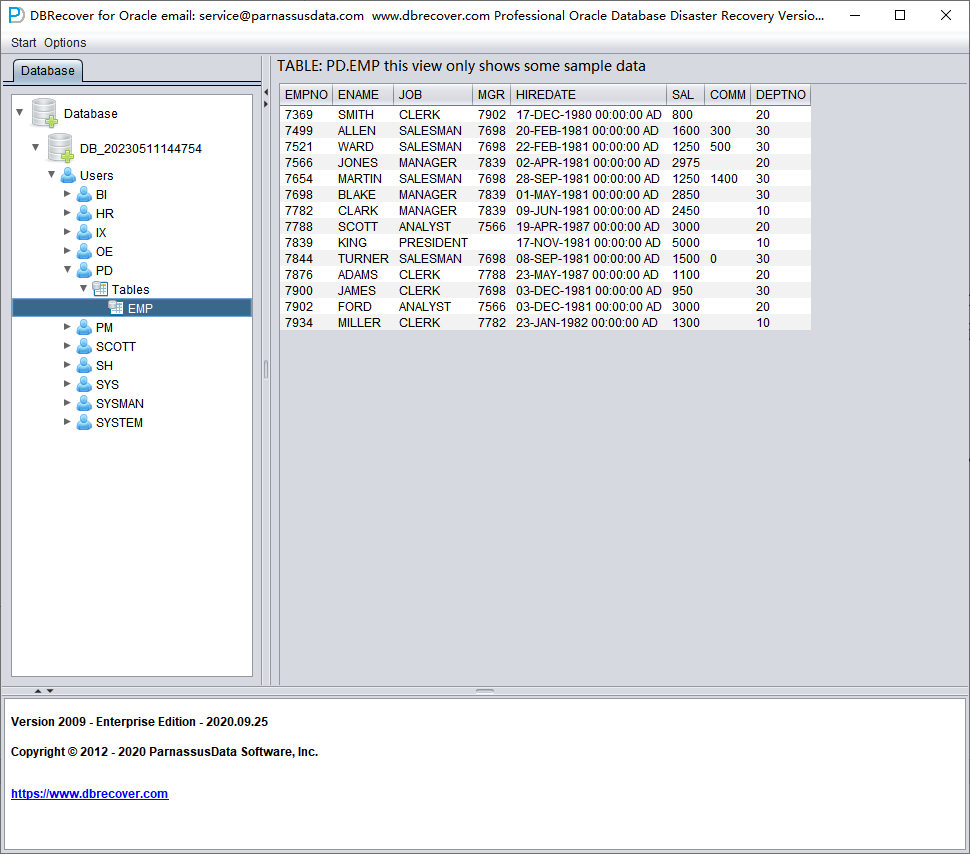
Sin comprar la licencia, podemos comprobar si DBRECOVER es capaz de recuperar suficientes datos visualizando las tablas, extrayendo al menos 10 000 filas y comprobando el número de filas recuperables.
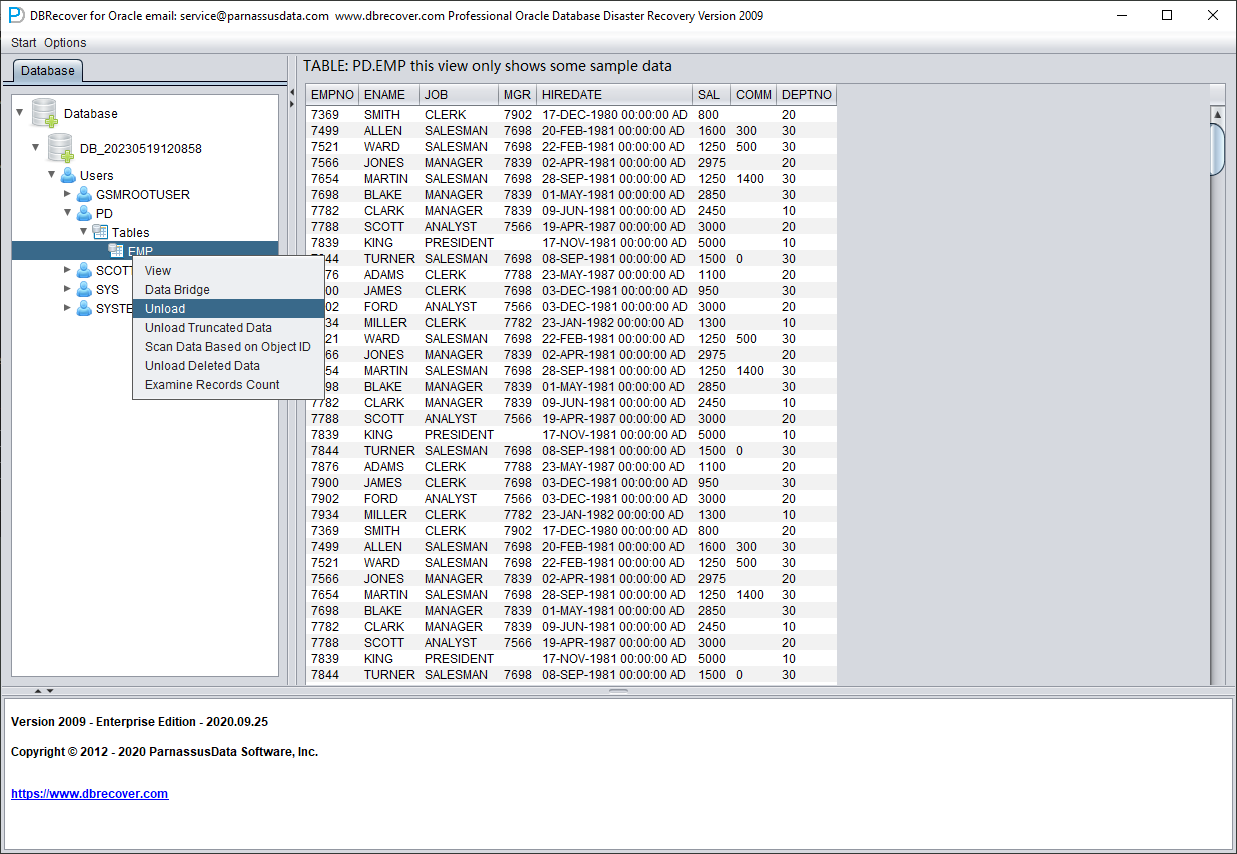
Tras seleccionar la tabla, pulse con el botón derecho UNLOAD; con esto se exportarán los datos de la tabla a formato texto:
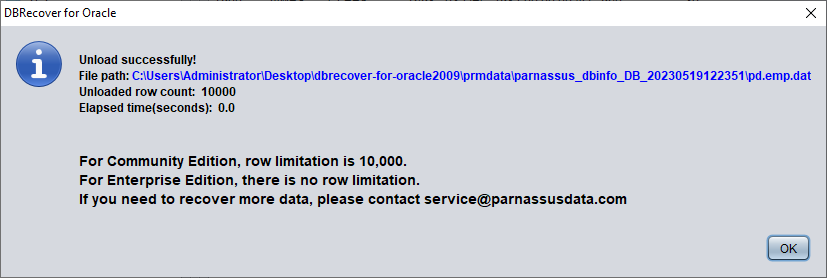
Sin una licencia registrada, cada tabla puede extraer como máximo 10 000 filas.
Para tablas con más de 10 000 filas, se puede usar la función de comprobar el número de filas recuperables para una verificación adicional. Seleccione la tabla que desee comprobar y pulse con el botón derecho EXAMINE RECORDS COUNT:
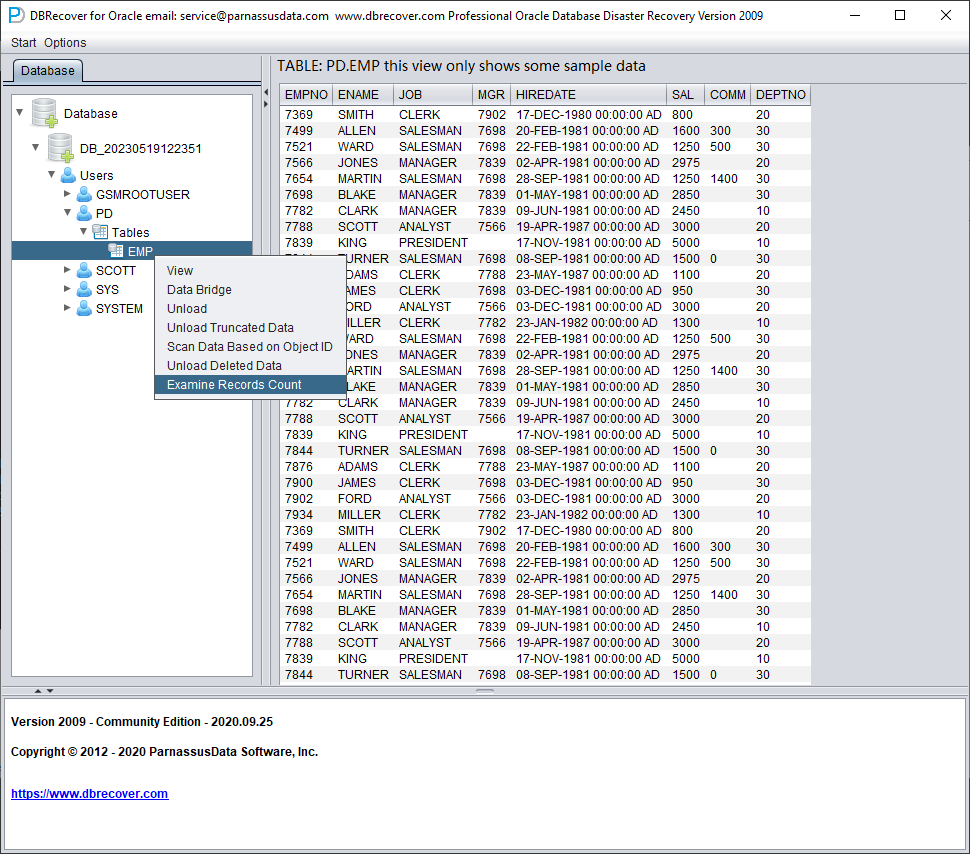
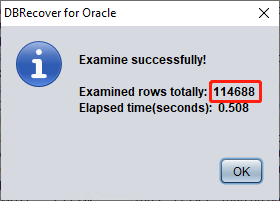
A partir de Oracle 10g se introdujo el job que recopila estadísticas de forma automática. Gracias a él podemos consultar las estadísticas históricas de la tabla, incluido el número de filas. En modo diccionario, cada vez que visualiza, extrae o comprueba una tabla, el software escribe los metadatos correspondientes en su fichero de log log_dbrecover.txt, ubicado en el directorio del software:
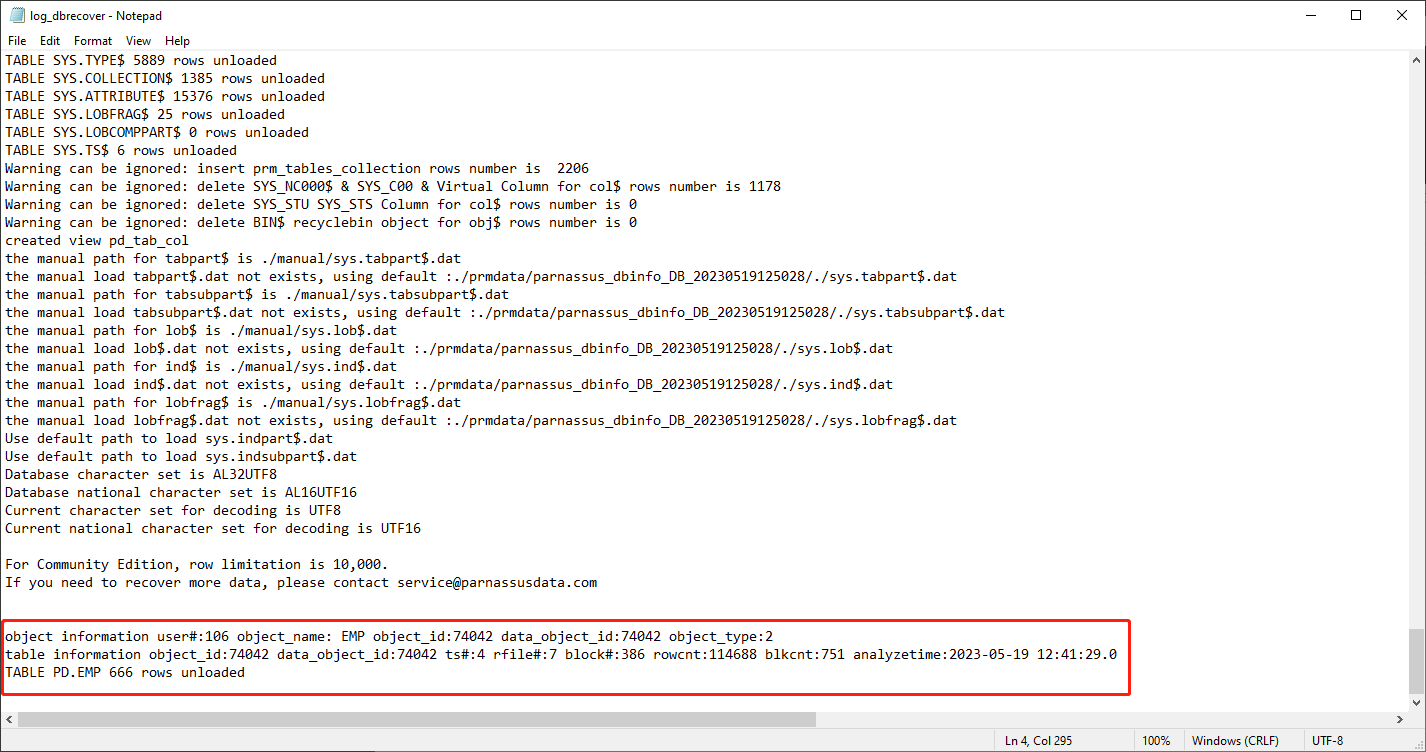
Revise el fichero de log:
object information user#:106 object_name: EMP object_id:74042 data_object_id:74042 object_type:2
table information object_id:74042 data_object_id:74042 ts#:4 rfile#:7 block#:386 rowcnt:114688 blkcnt:751 analyzetime:2023-05-19 12:41:29.0
TABLE PD.EMP 666 rows unloaded
En el log aparece bastante información útil:
| object_id | 74042 |
| data_object_id | 74042 |
| ts# | 4 |
| rfile# | 7 |
| block# | 386 |
| rowcnt | 114688 |
| blkcnt | 751 |
| analyzetime | 2023-05-19 12:41:29.0 |
En general, el error de las estadísticas no supera el 10 %, por lo que podemos comparar los resultados de la comprobación de filas con el rowcnt mostrado aquí. Por ejemplo, el rowcnt es 114688 (en tablas con menos de un millón de filas el error de las estadísticas es muy pequeño) y el resultado de EXAMINE también son 114688 filas, lo que valida la veracidad del resultado.
Cada usuario puede aplicar estas comprobaciones a las tablas que considere importantes según sus necesidades. Recomendamos verificar a fondo la integridad de los datos recuperables antes de adquirir la licencia.
Una vez realizadas las comprobaciones anteriores, iniciamos la transferencia con Data Bridge a nivel de SCHEMA de usuario. Haga clic derecho sobre el usuario que se desea recuperar y seleccione Data Bridge.
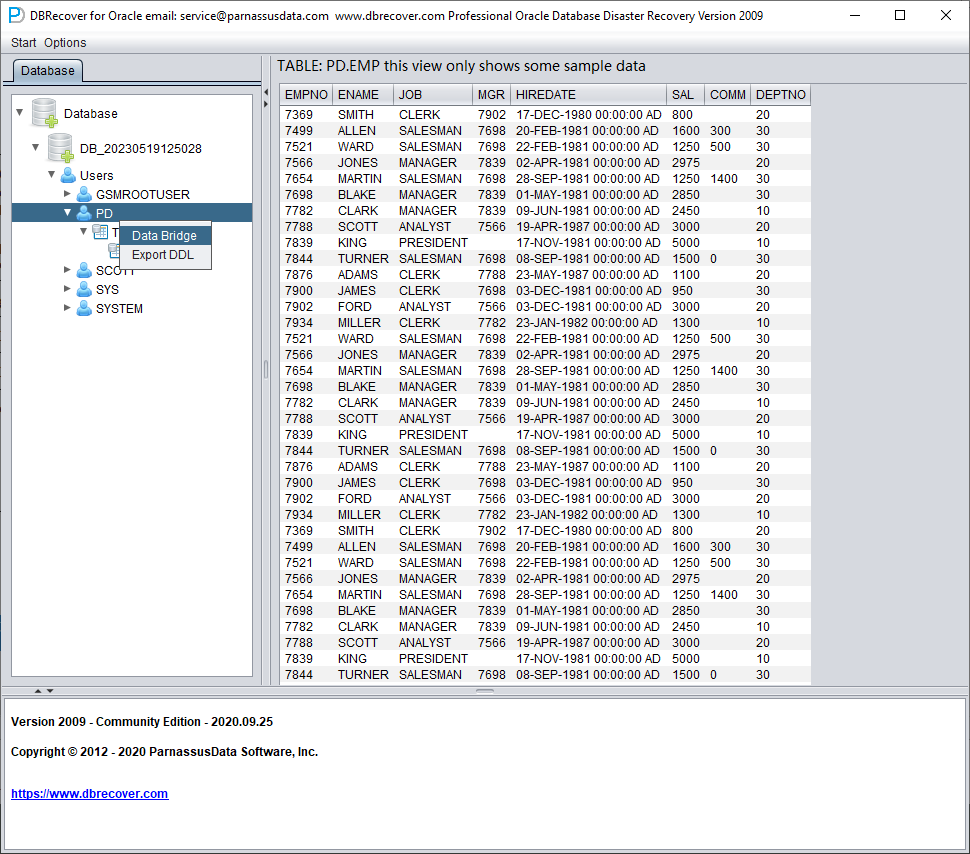
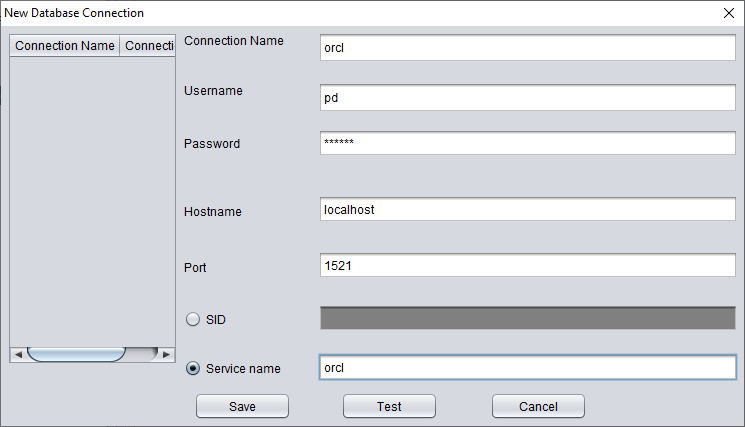
En la interfaz de Data Bridge a nivel de SCHEMA, pulse el botón «+» para añadir la información del enlace a la base de datos destino:
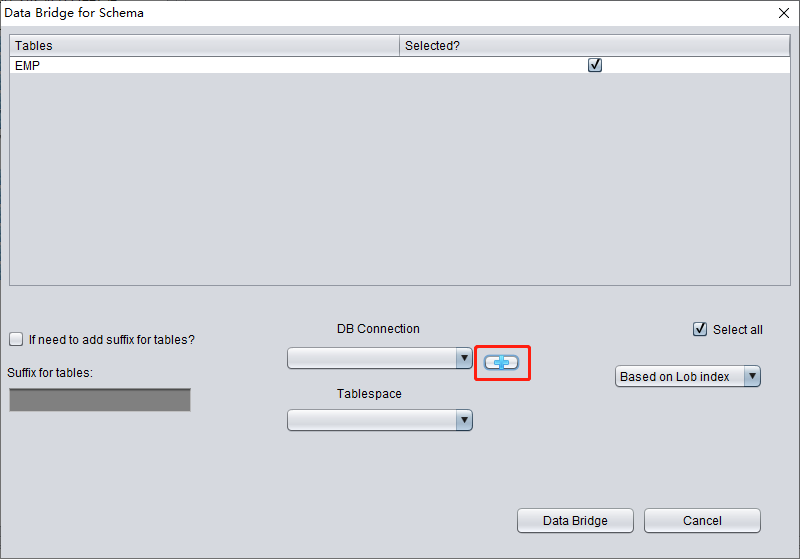
Introduzca la información del enlace a la instancia recién creada; aquí usamos el usuario PD.
Nota: DBRECOVER solo transfiere datos al usuario indicado en la información del enlace; es decir, si introduce PD aquí, los datos se transferirán a PD. Los clientes deben seguir un principio sencillo de correspondencia uno a uno: si hay que recuperar un usuario como EAS, cree el usuario EAS y su tablespace en la base de datos destino, otórguele los permisos necesarios (rol DBA) e indique EAS en este enlace para asegurar que los datos vayan a EAS. El PD que aparece aquí es solo un ejemplo. Si un cliente quiere recuperar varios usuarios, por ejemplo EAS, MES, NC001, etc., debe crear cada cuenta y su tablespace en la base de datos destino, asignarles los permisos necesarios (rol DBA) y crear varias entradas de DB Connection en DBRECOVER, indicando la entrada correspondiente al transferir cada SCHEMA.
Pulse TEST para probar la disponibilidad del enlace a la base de datos destino:
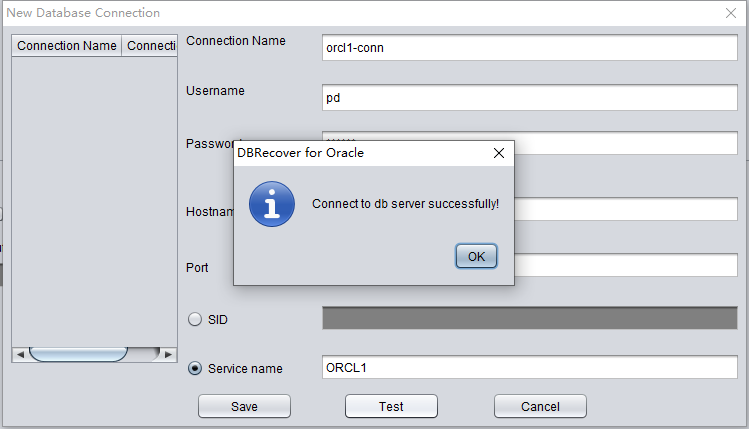
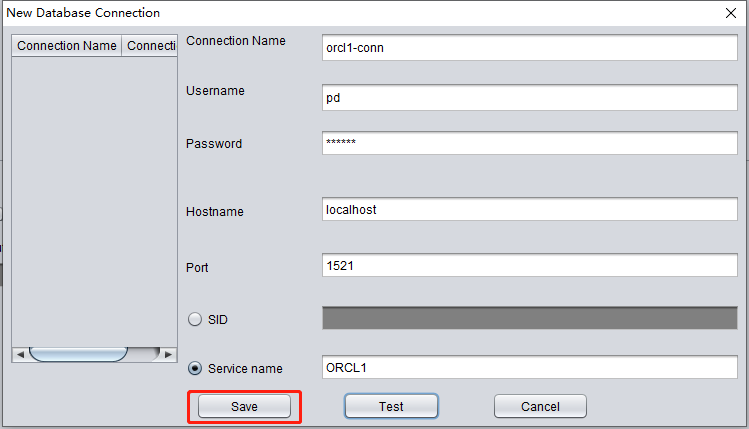
Si tiene éxito, pulse SAVE para guardar:
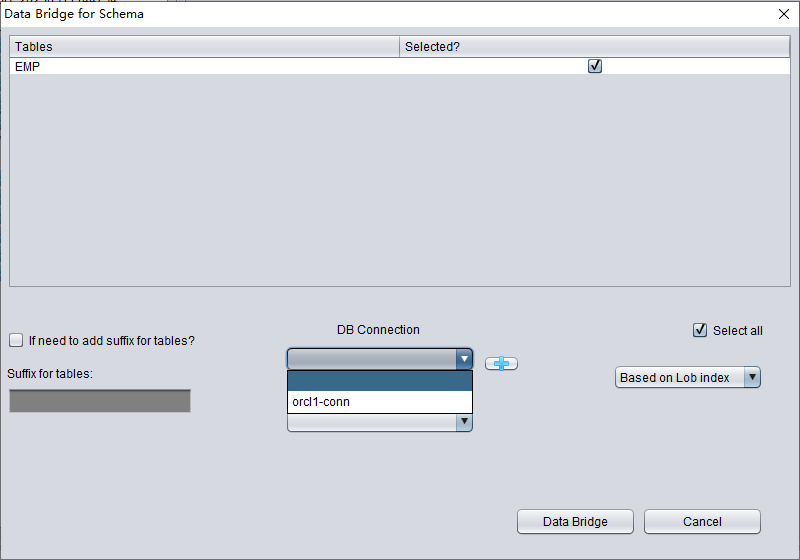
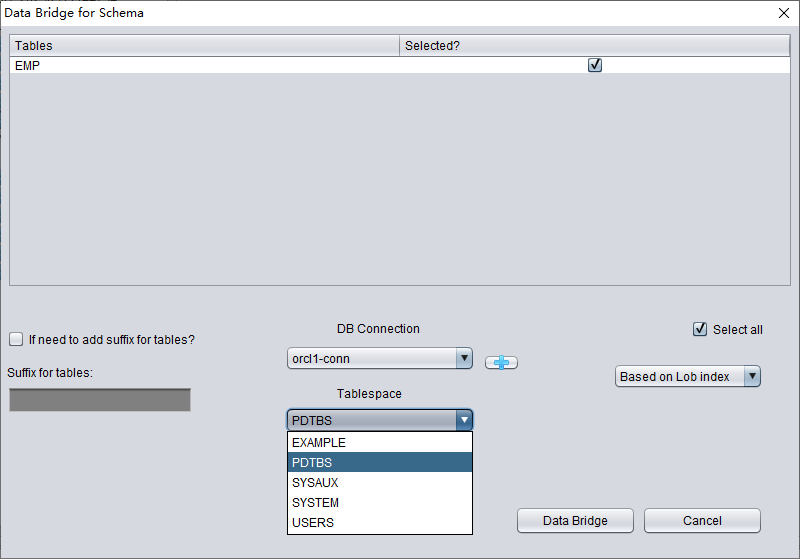
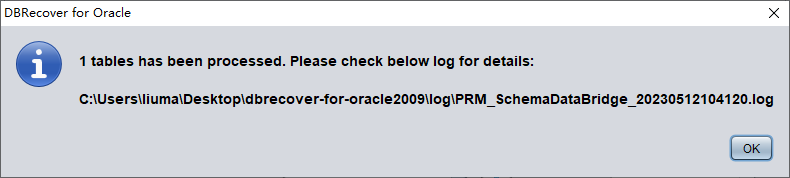
Compruebe los datos
SQL> show parameter db_name
NAME TYPE VALUE
----------------------------------- ---------------------- ------------------------------
db_name string ORCL1
SQL> select count(*) from pd.emp;
COUNT(*)
---------
14
Introducción al modo WIDE TABLE
Nota: el Data Bridge anterior utiliza por defecto el modo WIDE TABLE (tabla ancha) para transferir los datos, es decir, convierte todos los tipos CHAR, NCHAR, VARCHAR y NVARCHAR a su longitud máxima por defecto, 2000 o 4000. La finalidad es evitar el problema potencial de no poder insertar la cadena recuperada por tener el campo demasiado corto.
Si no quiere usar el modo de tabla ancha, vaya en la barra de menú a Options => Preferences.
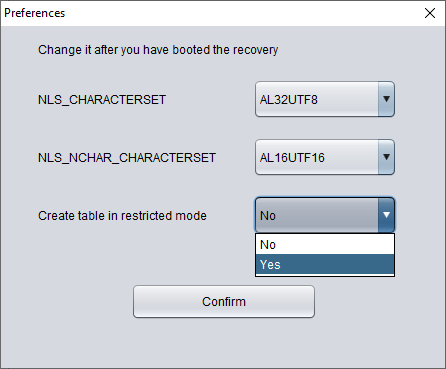
En la pantalla anterior, seleccionar «Yes» en el desplegable «Create table in restricted mode» impide que las tablas se creen en modo WIDE TABLE.
Introducción a la función EXPORT DDL
La operación de recuperación anterior se realizó sobre tablas individuales de un SCHEMA. Los objetos recuperados incluyen: la creación de las tablas correspondientes y la inserción de los datos recuperables.
Para recuperar índices, restricciones, vistas, triggers y otros objetos, se puede usar la función EXPORT DDL.
Seleccione el SCHEMA que desee recuperar, haga clic derecho y elija la función EXPORT DDL:
Los tipos de objeto que se pueden recuperar incluyen:
- Sentencia CREATE TABLE (atención: no incluye información de particiones)
- Sentencia CREATE INDEX (atención: no incluye información de particiones)
- Restricciones (constraints)
- Vistas
- Package, procedimiento almacenado y función
- Secuencias
- Triggers
- Sinónimos
- DBlink
Aquí seleccione la información del enlace a base de datos introducida previamente, que se utilizará temporalmente para procesar la información de DDL.

Una ventana emergente mostrará la ruta del fichero DDL SQL. Revíselo:
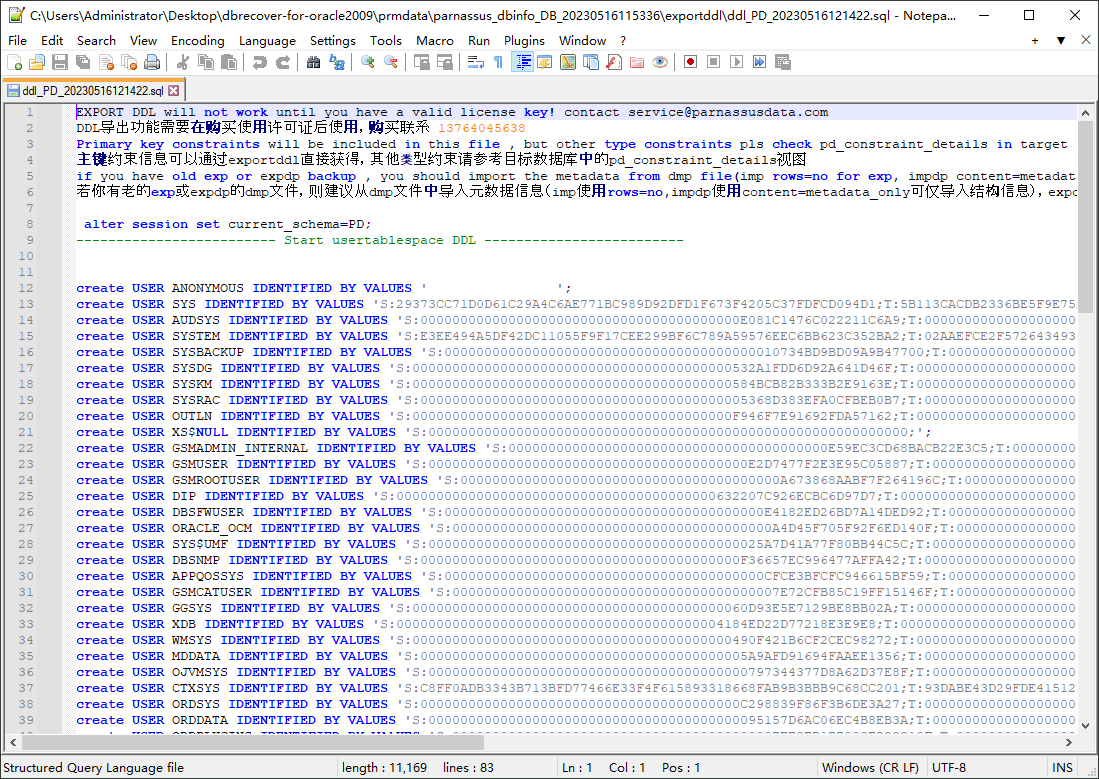
Nota: la función EXPORTDDL solo puede usarse con normalidad tras registrar una licencia de edición empresarial (LICENSE KEY) válida.
Las sentencias del fichero DDL SQL anterior, que crean índices, vistas y otros objetos, debe copiarlas el usuario y ejecutarlas bajo el usuario de base de datos correspondiente.
Si el usuario dispone de ficheros dmp antiguos de exp o expdp, se recomienda importar la información de metadatos desde el dmp (con rows=no en imp o content=metadata_only en impdp, para importar solo la información de estructura). La función exportddl carece de una pequeña parte de los metadatos, como las autorizaciones sobre objetos o las claves foráneas.
Introducción a la función LOAD FROM EXIST DICTS:
Si durante una recuperación real se encuentra con que el programa deja de responder, se queda colgado o lanza un error, tras reiniciar DBRECOVER puede emplear la función LOAD FROM EXIST DICTS para cargar directamente el estado anterior de la recuperación.
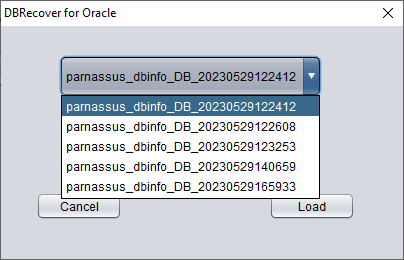
Los estados de recuperación se ordenan por fecha. Seleccione el adecuado y pulse el botón LOAD para cargarlo. Tanto el modo diccionario (DICTIONARY-MODE) como el modo sin diccionario (NON-DICTIONARY MODE) pueden usar esta función de carga rápida para evitar repetir operaciones.
Escenario de recuperación 2: Borrado accidental o pérdida total del tablespace SYSTEM
El administrador de sistemas de la empresa D borró por accidente el datafile en el que reside el tablespace SYSTEM de cierta base de datos, con lo que la base de datos quedó totalmente inarrancable y los datos eran inaccesibles. Sin backups disponibles, se puede usar DBRECOVER para extraer la información.
En este escenario, tras arrancar DBRECOVER y entrar en el Recovery Wizard, seleccione «Non-Dictionary mode» (modo sin diccionario):
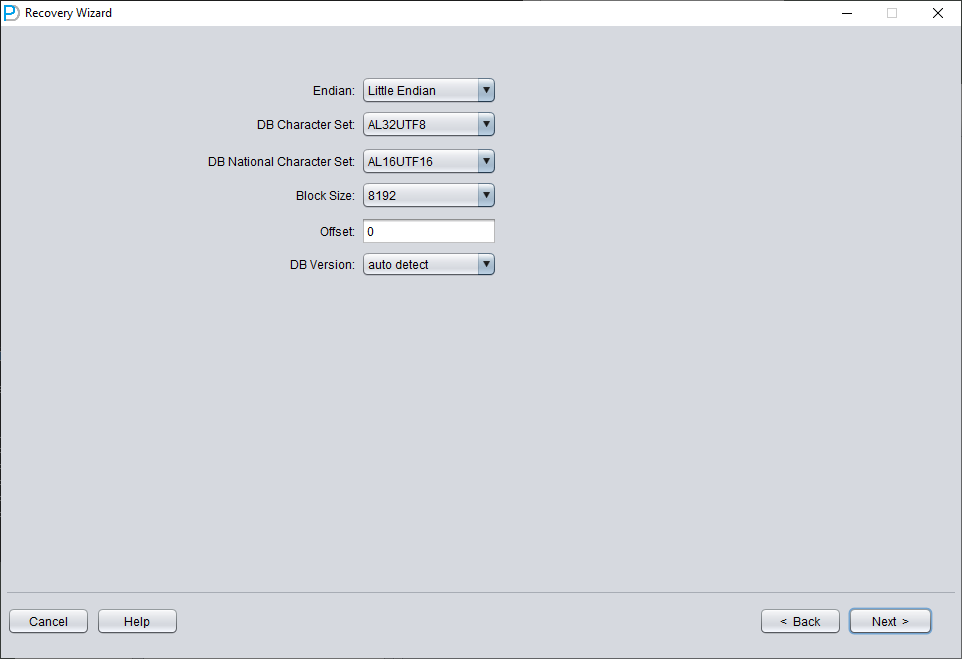
A continuación debe escoger el juego de caracteres correcto; de lo contrario, los datos resultantes saldrán como caracteres ilegibles.
En modo sin diccionario, hay que indicar tanto el juego de caracteres como el juego de caracteres nacional. Tras la pérdida del tablespace SYSTEM, los metadatos del juego de caracteres de la base de datos no se pueden leer, por lo que DBRECOVER necesita que se los proporcione. La extracción multilingüe en modo sin diccionario solo funciona correctamente cuando se han configurado tanto el juego de caracteres como los paquetes de idioma correspondientes.
De forma análoga al escenario 1, introduzca todos los datafiles de los que dispone actualmente (excluidos los ficheros temporales) y configure el Block Size y el OFFSET correctos:
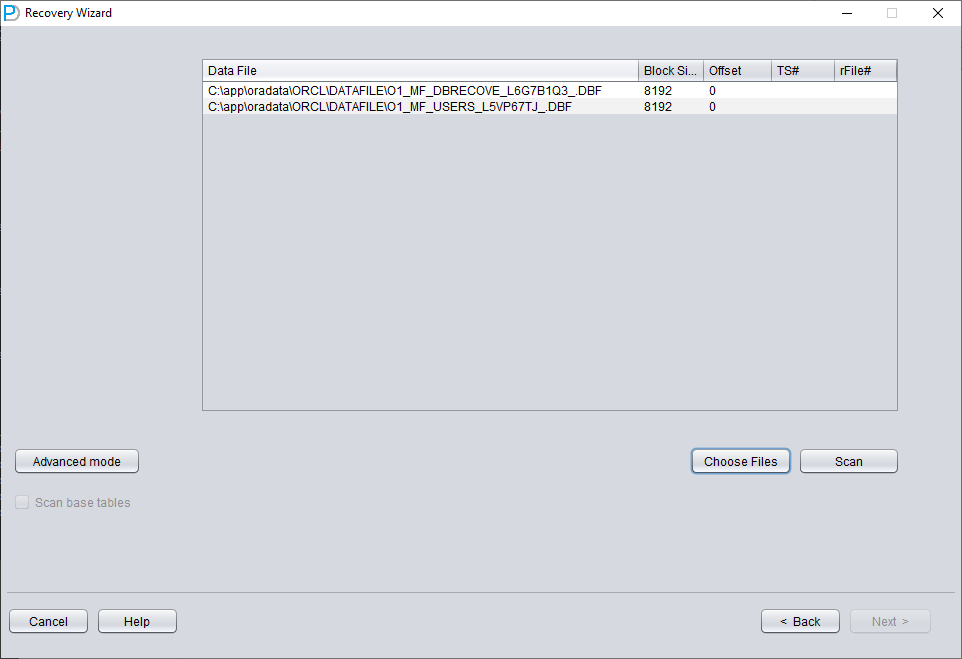
Después pulse SCAN. La función SCAN escanea la información de datos contenida en todos los datafiles.
Después haga clic derecho sobre el nodo de la base de datos en el árbol de la izquierda y elija SCAN EXTENT. Utilice el modo SCAN TABLE FROM SEGMENTS solo cuando pueda confirmar que todos los datafiles (salvo SYSTEM01.DBF) están disponibles. Su ventaja es que es algo más rápido, pero su grado de recuperación es menor que el del modo SCAN EXTENT cuando los datafiles están incompletos o dañados.
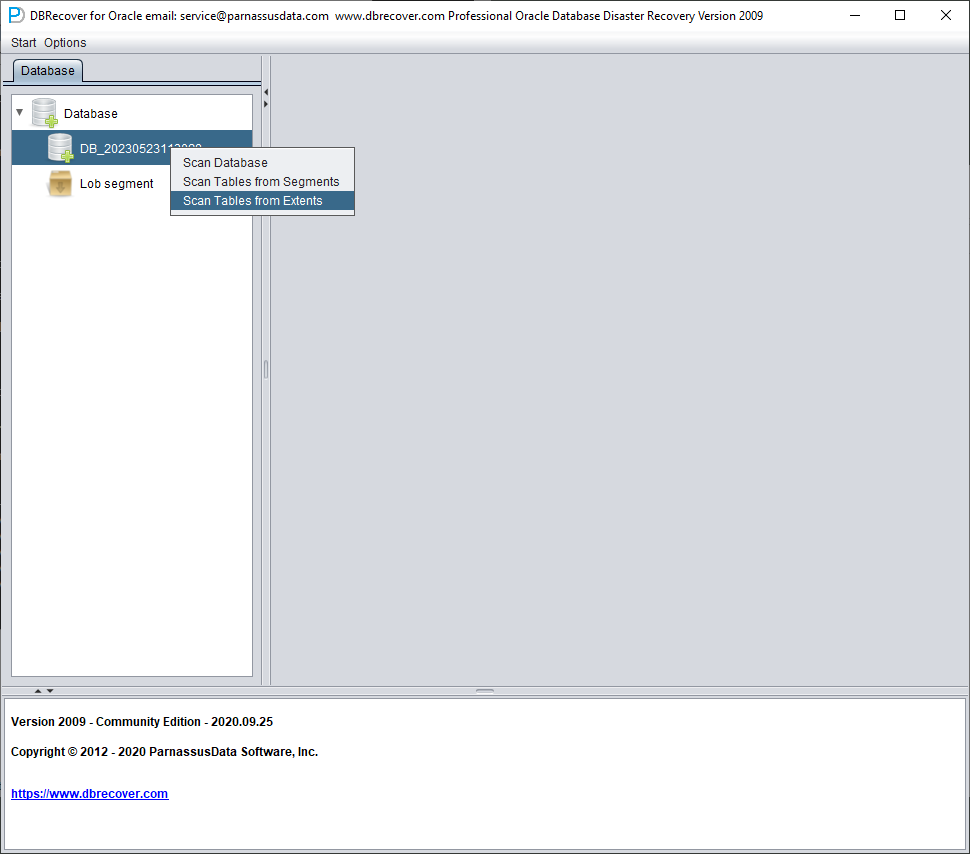
Cuando termina Scan Tables From Extents, puede desplegar el árbol del lado izquierdo de la interfaz principal:
Cada nodo del árbol representa un segmento de datos de una tabla heap normal o de una partición, y su nombre es «obj» seguido del DATA OBJECT ID registrado en ese segmento.
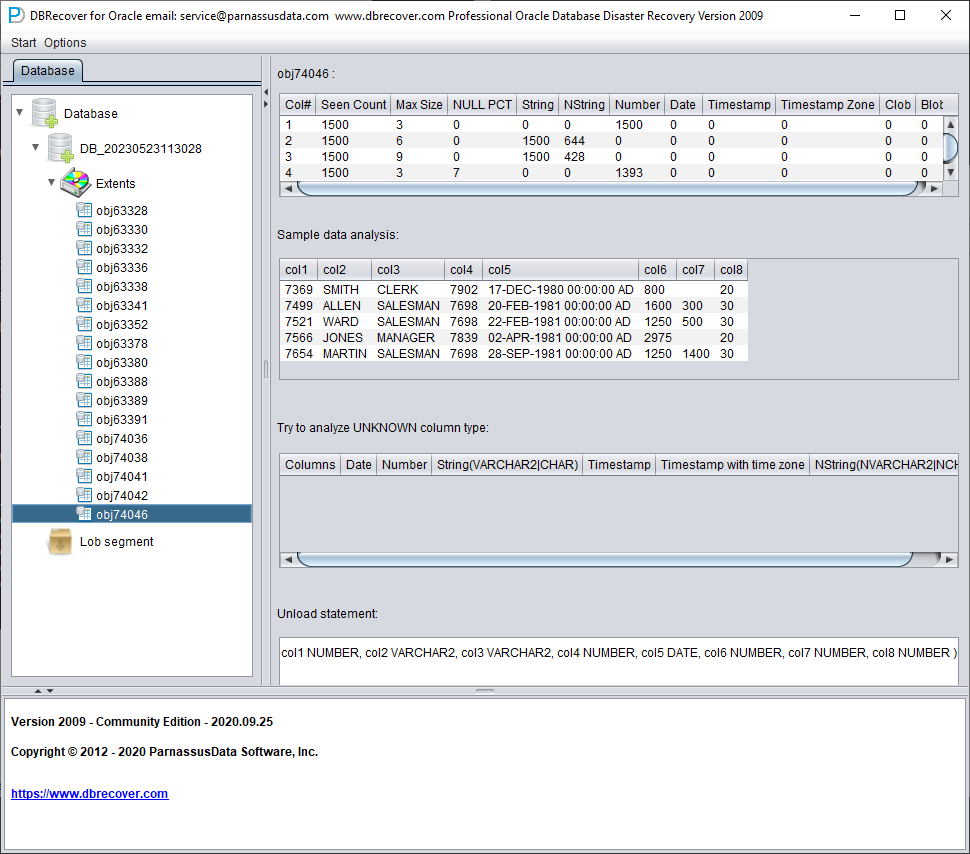
Haga clic en un nodo y observe la barra lateral derecha de la interfaz principal:
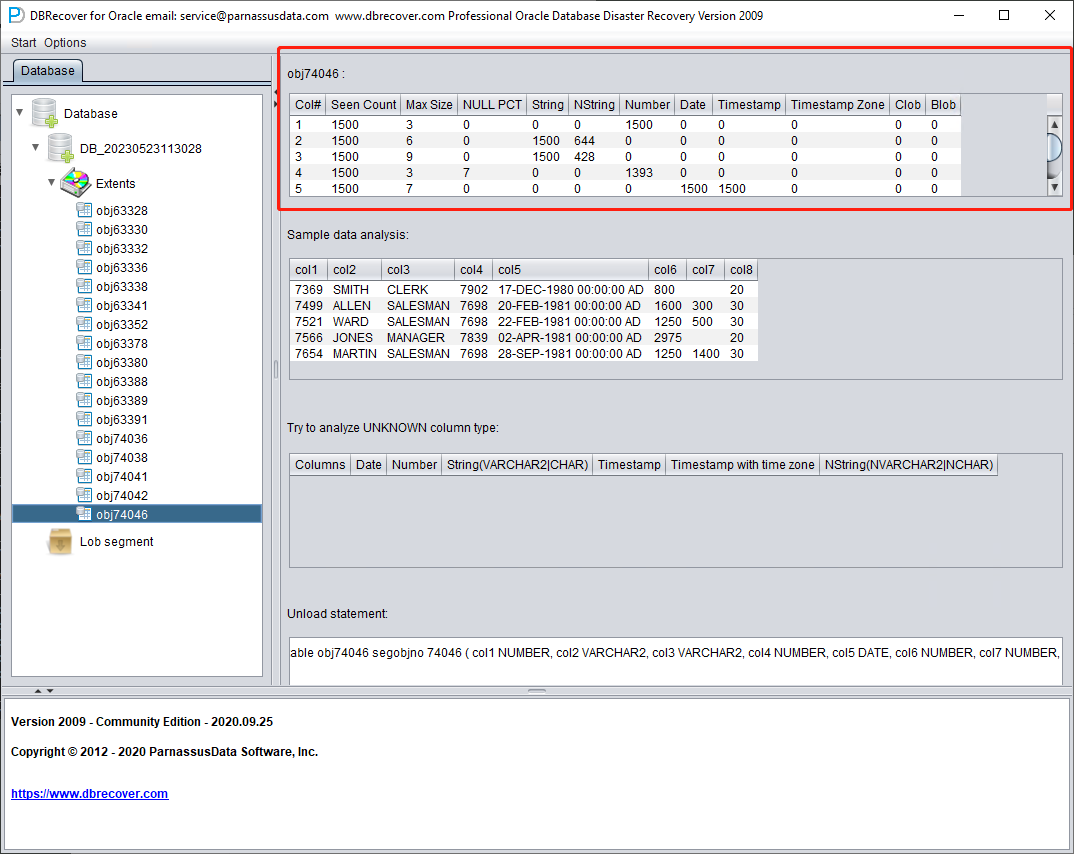
Análisis del tipo de campo
Como el tablespace SYSTEM se ha perdido, el modo sin diccionario no dispone de la información de estructura de las tablas. Esa información incluye los nombres y tipos de los campos, y en ORACLE solo se guarda como información del diccionario, no en la propia tabla. Cuando el usuario solo conserva el tablespace donde residen los datos de la aplicación, hay que adivinar el tipo de cada campo a partir de los datos ROW del segmento. Aquí podemos analizar más de diez tipos de datos habituales:
- Cadenas: incluyen char y varchar
- NString, cadenas en idioma nacional: nchar, nvarchar
- Number, tipo numérico
- Tipo Date
- Tipo TimeStamp
- Tipo TimeStamp Zone, con zona horaria
- CLOB
- BLOB
Análisis de datos de muestra
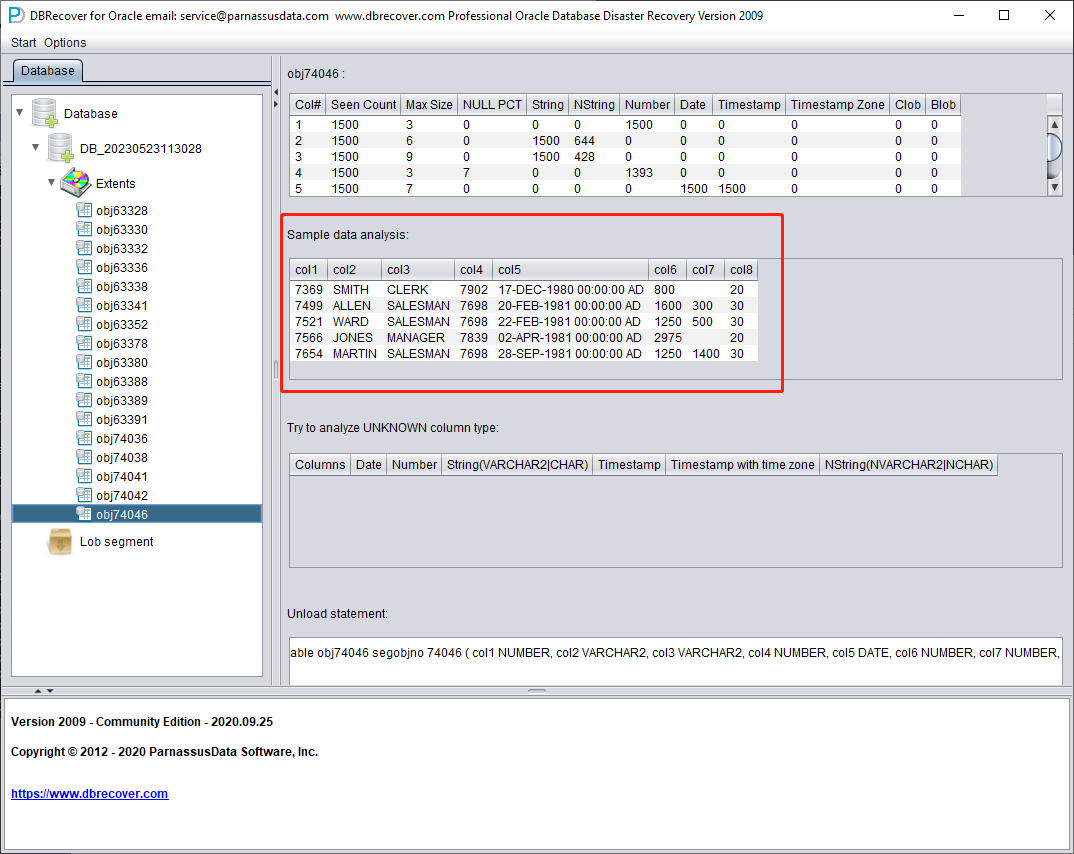
Esta sección analiza 10 registros basándose en los resultados del análisis de tipo de campo y muestra el resultado del parseo. Los datos de muestra ayudan a los usuarios a entender qué datos hay realmente en este segmento. Si en el segmento hay menos de 10 registros, se mostrarán todos.
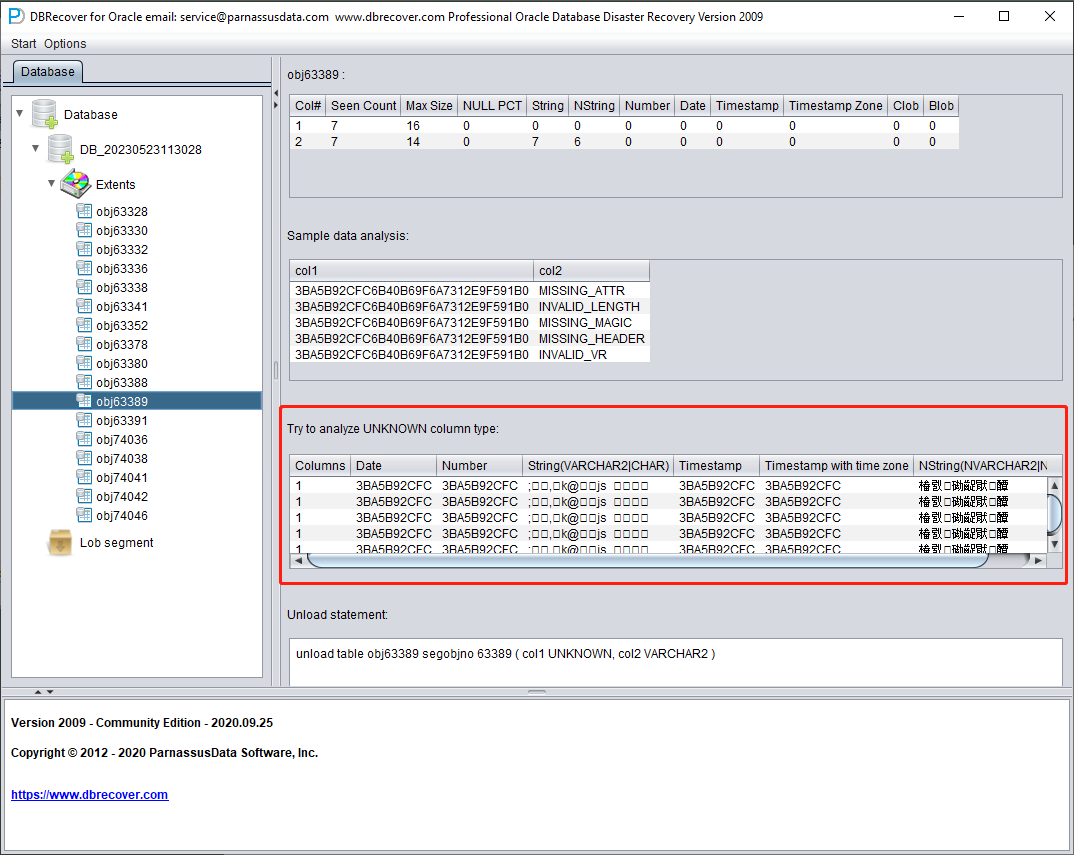
TRY TO ANALYZE UNKNOWN column type:
Esta sección está pensada para los campos cuyo tipo no ha podido confirmar plenamente la función de análisis. Intenta interpretarlos con distintos tipos de campo y los presenta al usuario para que decida cuál es realmente.
Los campos cuyo tipo no se puede confirmar suelen darse en los siguientes casos:
- RAW o LONG RAW
- Tipos de datos no soportados, como XDB.XDB$RAW_LIST_T, XMLTYPE, tipos definidos por el usuario, etc.
- El propio bloque de datos está gravemente dañado
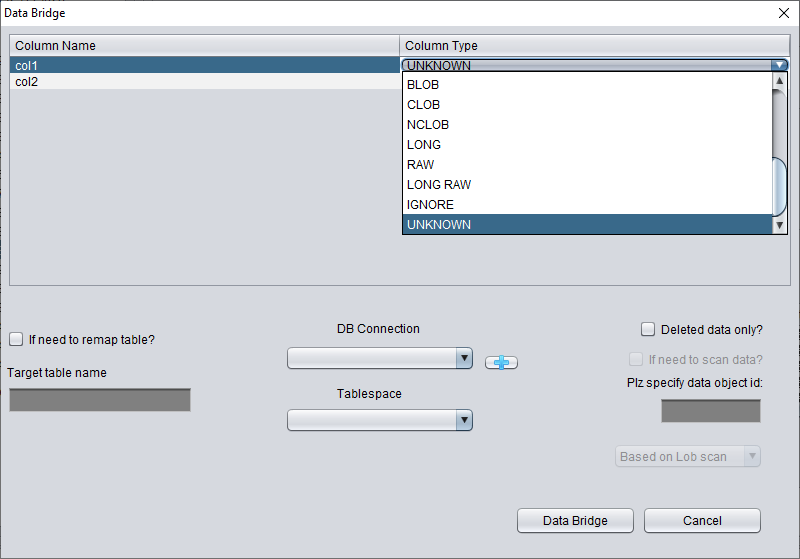
En este «Non-Dictionary Mode» también se pueden emplear los métodos convencionales y el de Data Bridge. La diferencia principal frente al modo diccionario es que, en el modo sin diccionario, el usuario puede decidir él mismo el tipo de cada campo durante el Data Bridge. Como muestra la figura siguiente, algunos tipos de campo aparecen como UNKNOWN, es decir, desconocidos.
Si el usuario conoce la estructura original de la tabla (también puede obtenerla de la documentación del desarrollador de la aplicación), puede rellenar él mismo los Column Type correctos para conseguir transferir los datos al destino con éxito.
Escenario de recuperación 3: Cifrado por ransomware o daños en los datafiles
El malware de tipo ransomware cifra parte o todo el contenido de los datafiles de ORACLE. Como los datafiles suelen ser de gran tamaño, cifrar el fichero completo puede llevar mucho tiempo, así que algunos ransomwares optan por cifrar únicamente un tramo continuo o aleatorio en la cabecera del datafile.
Frente a este tipo de daño por cifrado parcial, podemos intentar usar DBRECOVER para recuperar los datos.
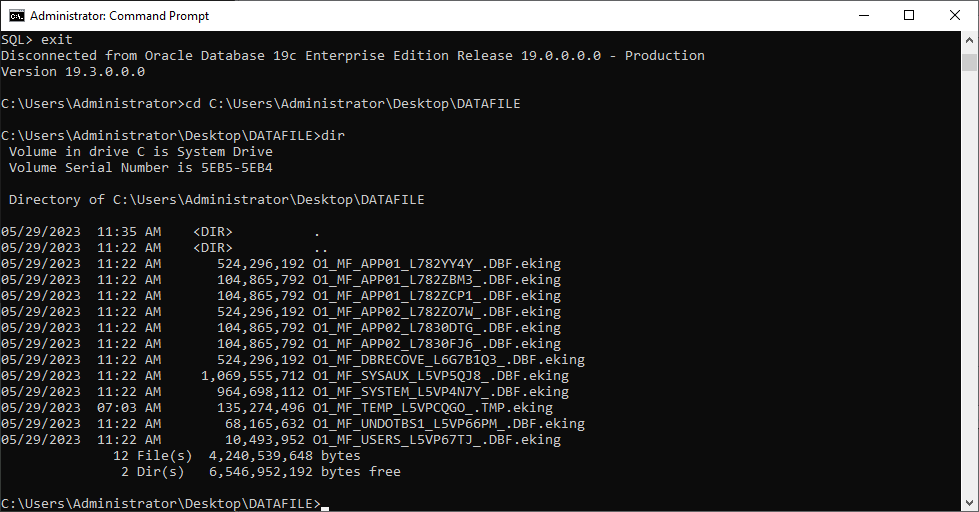
Como la cabecera del datafile está dañada, hay que averiguar el número de tablespace (TS#) y el número relativo de archivo (RFILE#) de cada datafile observando el contenido de SYSTEM01.DBF.
A continuación se muestra el listado de datafiles:
O1_MF_APP01_L782YY4Y_.DBF.eking
O1_MF_APP01_L782ZBM3_.DBF.eking
O1_MF_APP01_L782ZCP1_.DBF.eking
O1_MF_APP02_L782ZO7W_.DBF.eking
O1_MF_APP02_L7830DTG_.DBF.eking
O1_MF_APP02_L7830FJ6_.DBF.eking
O1_MF_DBRECOVE_L6G7B1Q3_.DBF.eking
O1_MF_SYSAUX_L5VP5QJ8_.DBF.eking
O1_MF_SYSTEM_L5VP4N7Y_.DBF.eking
O1_MF_TEMP_L5VPCQGO_.TMP.eking
O1_MF_UNDOTBS1_L5VP66PM_.DBF.eking
O1_MF_USERS_L5VP67TJ_.DBF.eking
En el ejemplo anterior, los ficheros tienen el sufijo de cifrado eking.
Tenga en cuenta que TEMP, UNDOTBS1 y SYSAUX son irrelevantes para nuestro trabajo de recuperación, así que puede ignorar esos ficheros.
Primero arrancamos DBRECOVER usando el modo diccionario DICT-MODE.
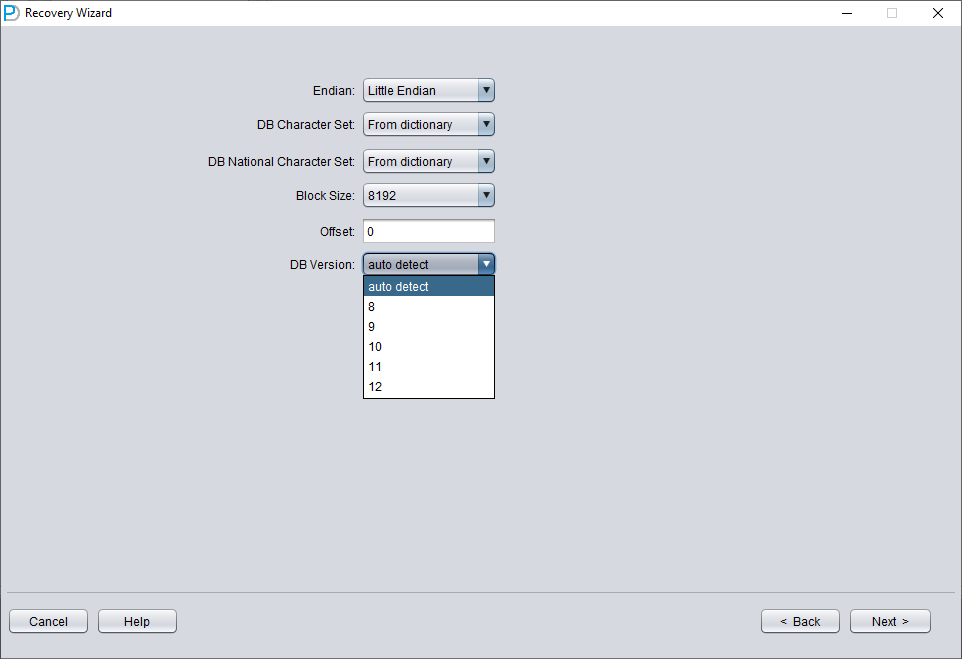
Elija DB VERSION según la situación real. Para instancias superiores a 12c, como 18c, 19c, etc., seleccione 12.
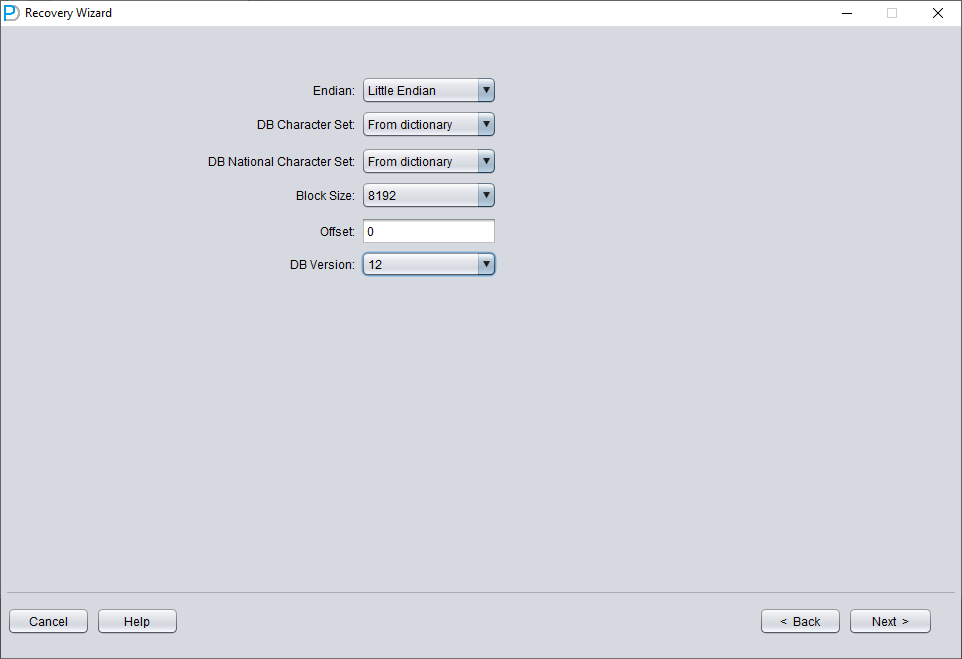
Añada solo SYSTEM01.DBF e indique TS# = 0 y rFILE# = 1 (estos valores son fijos).
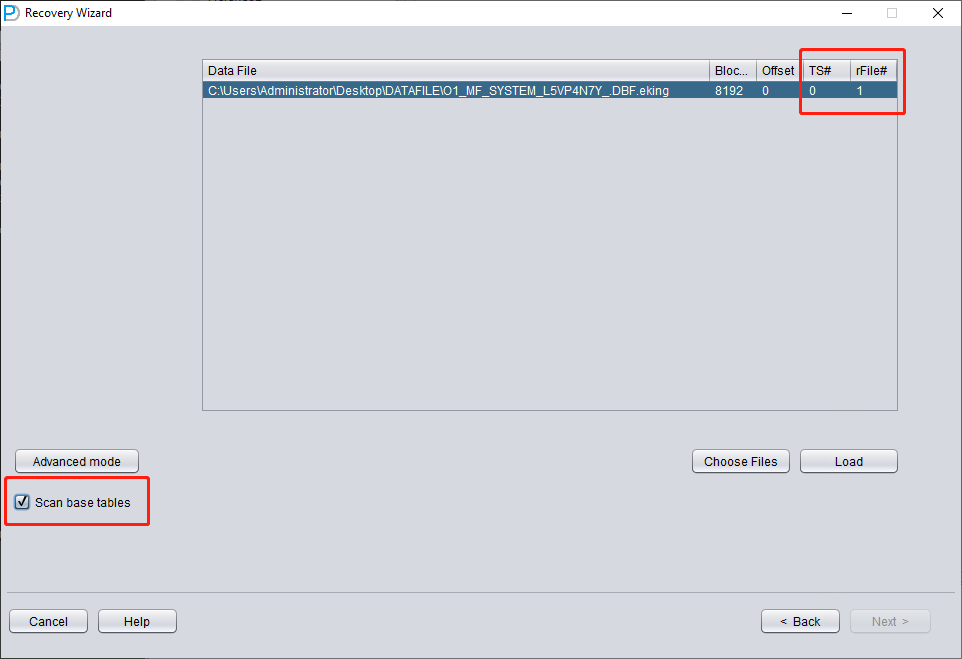
Marcar arriba la opción «SCAN BASE TABLES» permite enfrentarse con más eficacia a situaciones de corrupción.
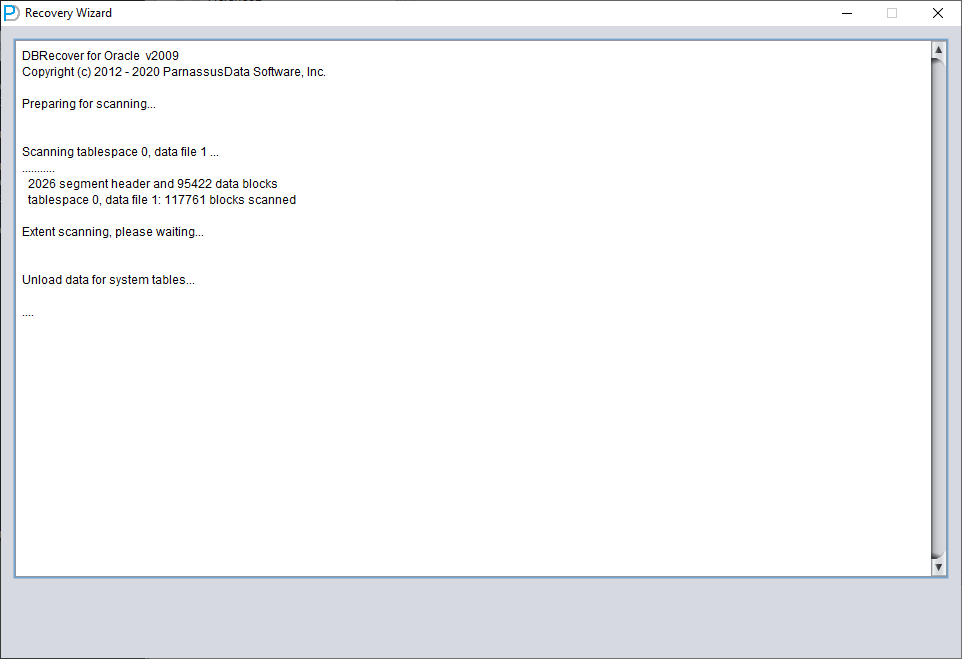
Tras pulsar el botón LOAD, DBRECOVER escanea SYSTEM01.DBF en su totalidad y localiza en él los datos de las tablas base del diccionario de datos.
Abrimos el nodo del usuario SYS y buscamos las dos tablas base TS$ y FILE$:
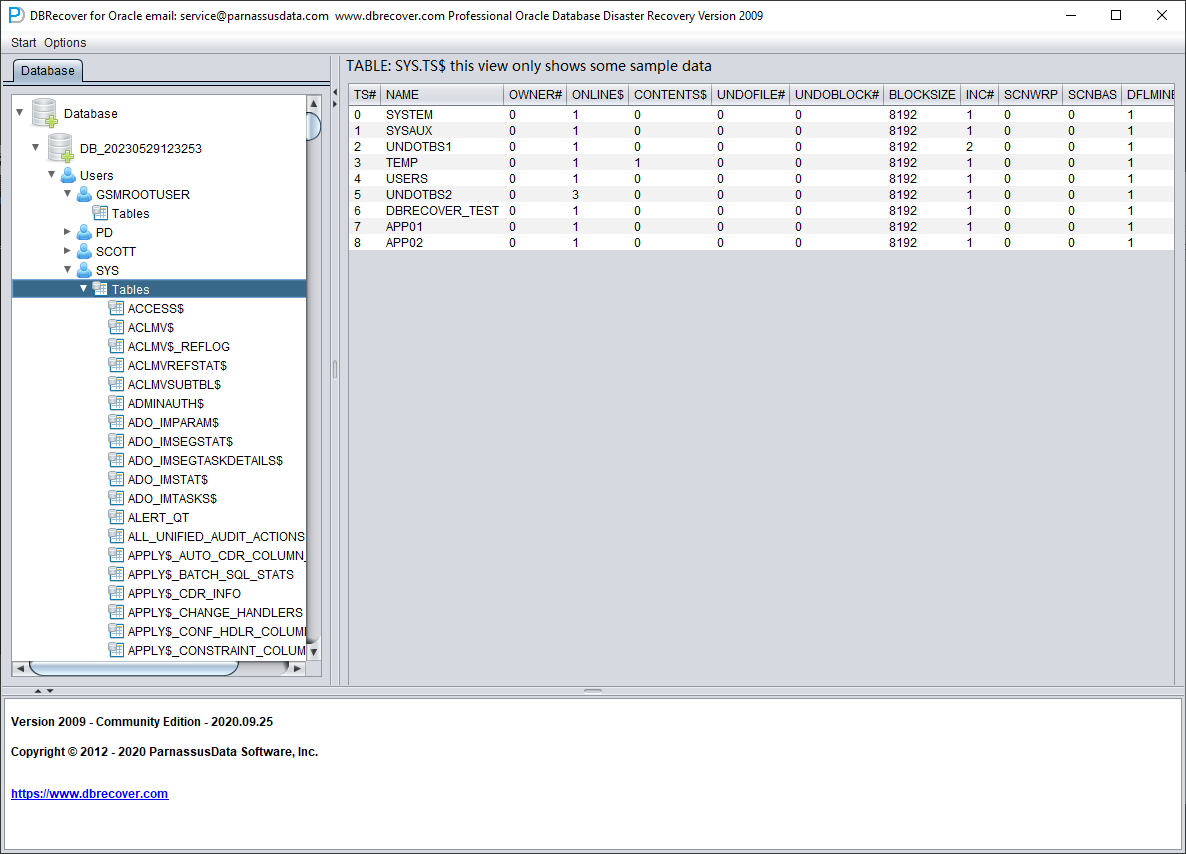
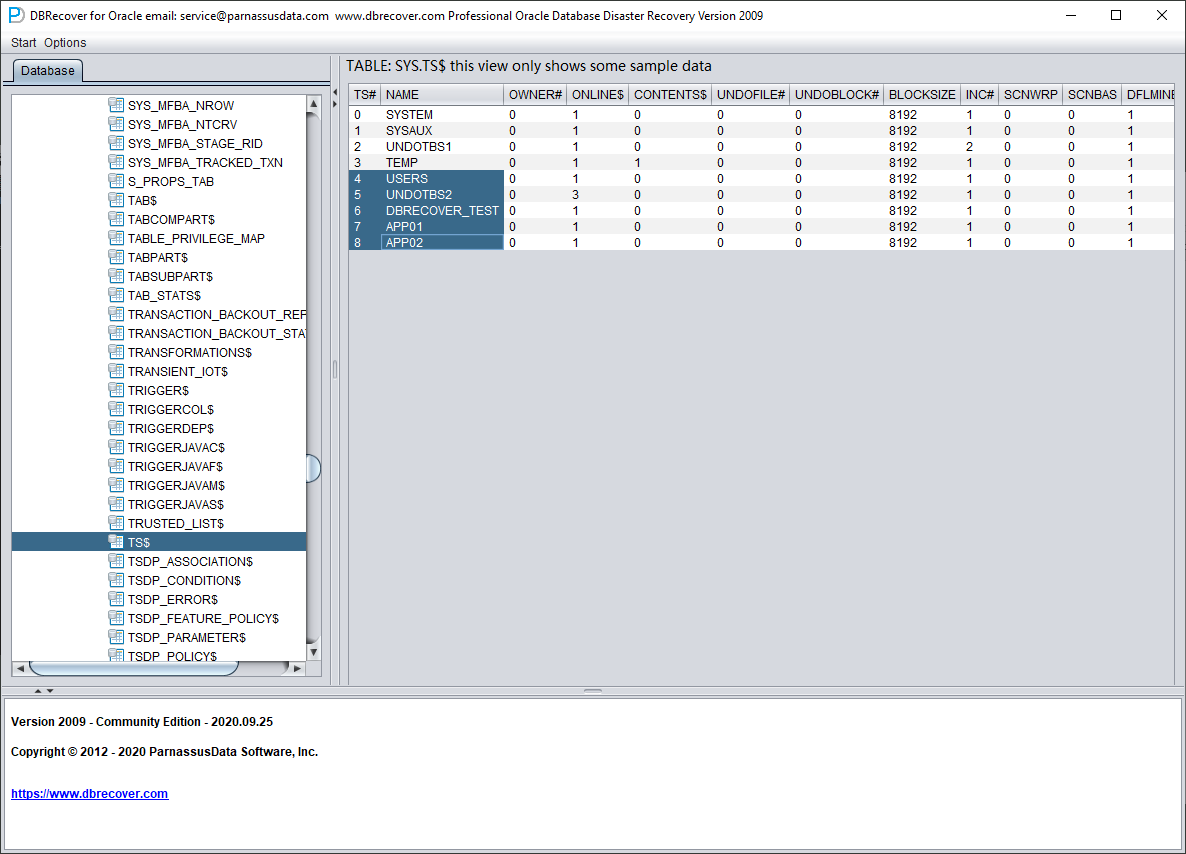
La tabla TS$ almacena la información de los tablespaces; la columna TS# es el número de tablespace. Obtenemos lo siguiente:
| TS# | NOMBRE |
| 0 | SYSTEM |
| 1 | SYSAUX |
| 2 | UNDOTBS1 |
| 3 | TEMP |
| 4 | USERS |
| 5 | UNDOTBS2 |
| 6 | DBRECOVER_TEST |
| 7 | APP01 |
| 8 | APP02 |
Es decir, el TS# del tablespace APP01 es 7 y el del tablespace APP02 es 8.
La tabla FILE$ almacena la información de los datafiles:
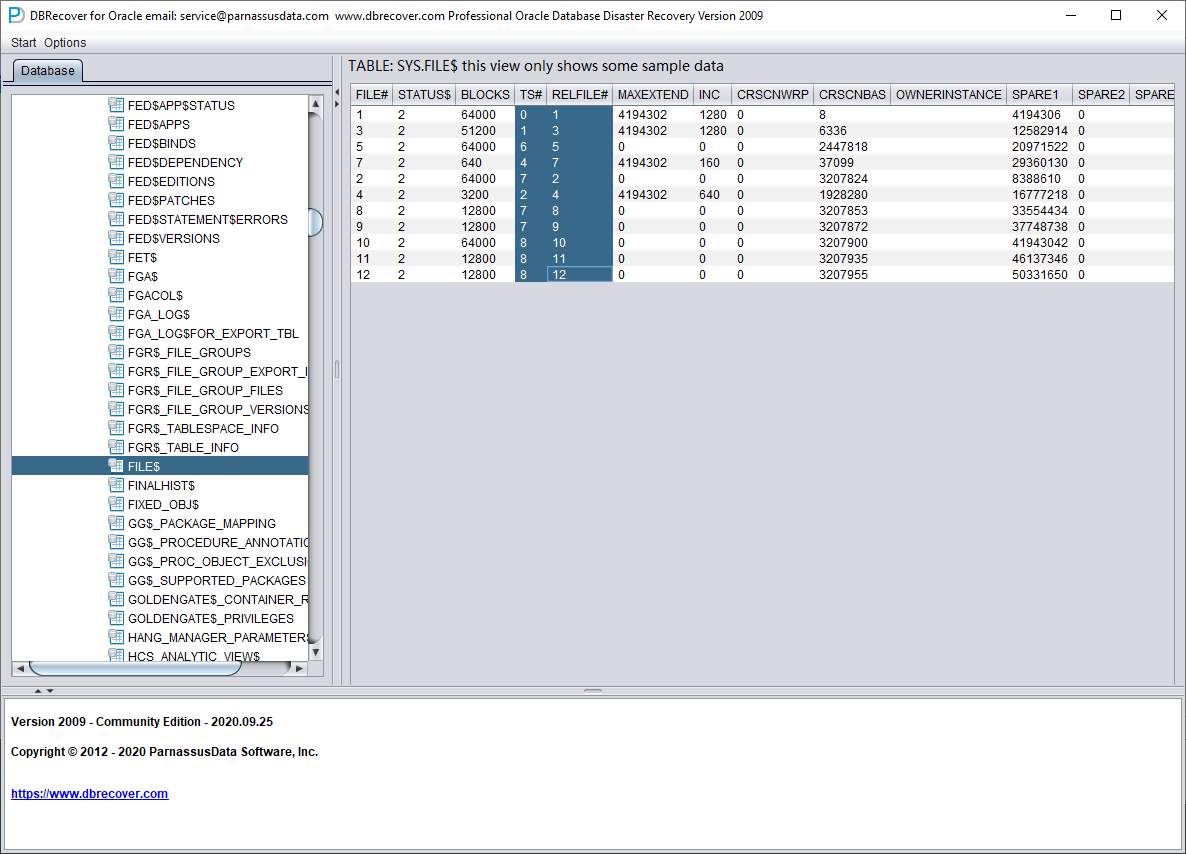
Lo que nos interesa son las columnas TS# y RELFILE#.
| TS# | RELFILE# |
| 0 | 1 |
| 1 | 3 |
| 6 | 5 |
| 4 | 7 |
| 7 | 2 |
| 2 | 4 |
| 7 | 8 |
| 7 | 9 |
| 8 | 10 |
| 8 | 11 |
| 8 | 12 |
Cruzando y combinando la información de ambas tablas obtenemos:
| TS# | RELFILE# | Nombre del tablespace |
| 0 | 1 | SYSTEM |
| 1 | 3 | SYSAUX |
| 6 | 5 | DBRECOVER_TEST |
| 4 | 7 | USERS |
| 7 | 2 | APP01 |
| 2 | 4 | UNDOTBS1 |
| 7 | 8 | APP01 |
| 7 | 9 | APP01 |
| 8 | 10 | APP02 |
| 8 | 11 | APP02 |
| 8 | 12 | APP02 |
Tras descartar SYSAUX, UNDOTBS1 y el tablespace SYSTEM ya conocido, quedan únicamente:
| TS# | RELFILE# | Nombre del tablespace |
| 6 | 5 | DBRECOVER_TEST |
| 4 | 7 | USERS |
| 7 | 2 | APP01 |
| 7 | 8 | APP01 |
| 7 | 9 | APP01 |
| 8 | 10 | APP02 |
| 8 | 11 | APP02 |
| 8 | 12 | APP02 |
Lista de nombres de datafiles correspondientes:
O1_MF_APP01_L782YY4Y_.DBF.eking
O1_MF_APP01_L782ZBM3_.DBF.eking
O1_MF_APP01_L782ZCP1_.DBF.eking
O1_MF_APP02_L782ZO7W_.DBF.eking
O1_MF_APP02_L7830DTG_.DBF.eking
O1_MF_APP02_L7830FJ6_.DBF.eking
O1_MF_DBRECOVE_L6G7B1Q3_.DBF.eking
O1_MF_USERS_L5VP67TJ_.DBF.eking
Cruzando ambas tablas se obtiene la correspondencia entre fichero y tablespace. En bases de datos con Oracle Managed Files (OMF, controlado por db_create_file_dest), si un tablespace tiene varios datafiles se pueden ordenar por nombre y ese orden coincide con RELFILE#. En bases de datos con nombres de fichero gestionados por el usuario, las instalaciones suelen seguir convenciones como APP01{XX} (por ejemplo APP0101, APP0102), de las que también se puede derivar la misma correspondencia.
Con el razonamiento anterior llegamos a una tabla de información completa:
| TS# | RFILE# | Nombre del tablespace | NOMBRE DEL FICHERO |
| 6 | 5 | DBRECOVER_TEST | O1_MF_DBRECOVE_L6G7B1Q3_.DBF.eking |
| 4 | 7 | USERS | O1_MF_USERS_L5VP67TJ_.DBF.eking |
| 7 | 2 | APP01 | O1_MF_APP01_L782YY4Y_.DBF.eking |
| 7 | 8 | APP01 | O1_MF_APP01_L782ZBM3_.DBF.eking |
| 7 | 9 | APP01 | O1_MF_APP01_L782ZCP1_.DBF.eking |
| 8 | 10 | APP02 | O1_MF_APP02_L782ZO7W_.DBF.eking |
| 8 | 11 | APP02 | O1_MF_APP02_L7830DTG_.DBF.eking |
| 8 | 12 | APP02 | O1_MF_APP02_L7830FJ6_.DBF.eking |
Vuelva a abrir DBRECOVER y cámbielo al modo diccionario:
Sigue siendo necesario seleccionar la versión de base de datos (DB VERSION).
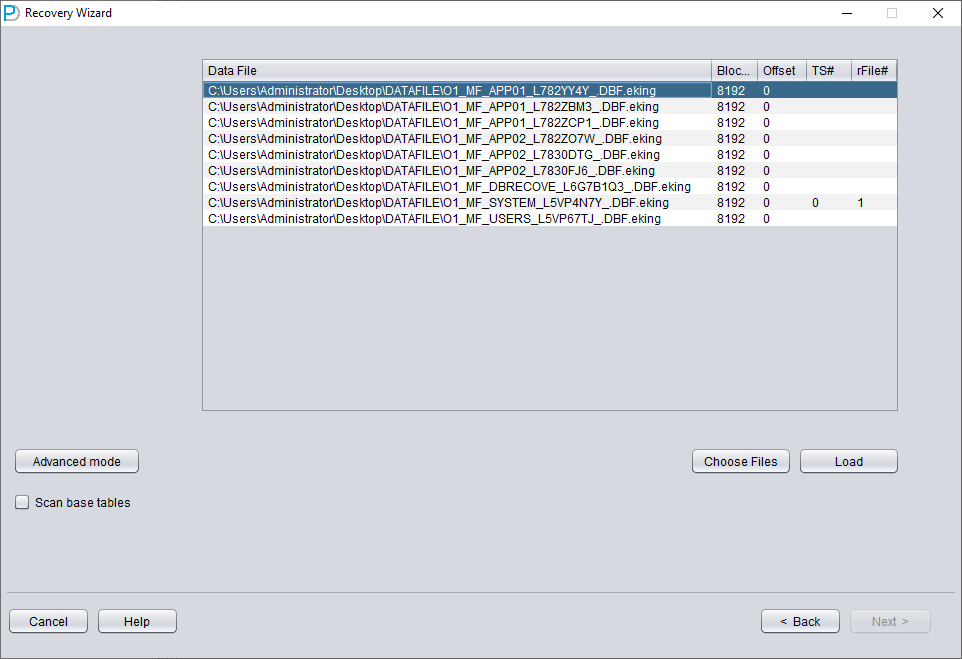
Añada todos los datafiles necesarios (todos los que puedan contener datos de usuario; no hace falta añadir UNDOTBS1, TEMP ni SYSAUX) y no se olvide nunca de SYSTEM01.DBF (es obligatorio incluirlo).
Rellene los valores de TS# y RFILE# según la tabla que confeccionó antes:
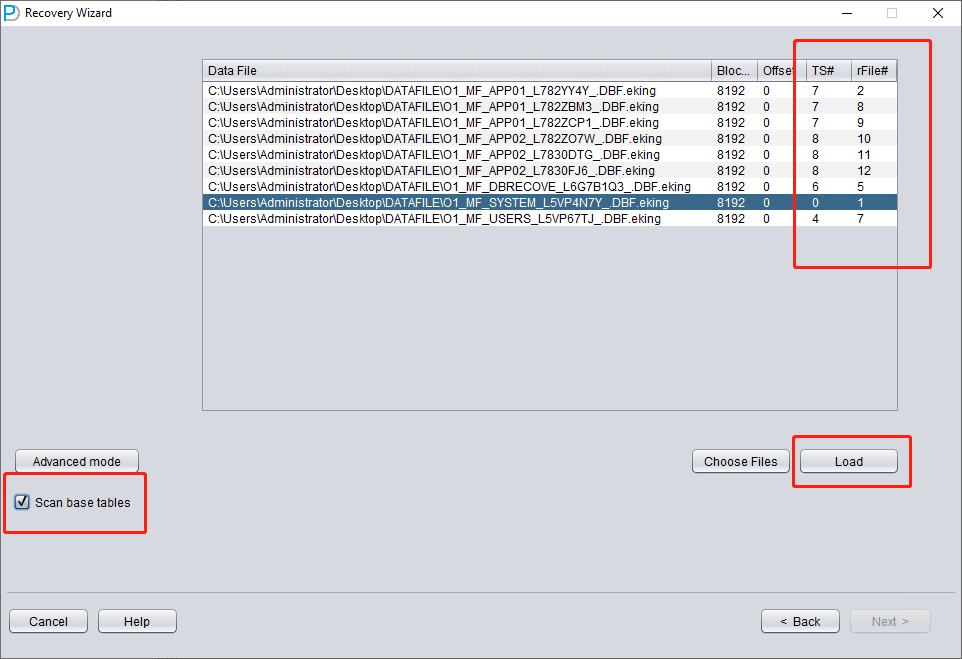
Si los datos introducidos son correctos y el daño por cifrado no es muy grave, podrá leer los datos directamente:
Las distintas variantes de ransomware se comportan de forma diferente, por lo que una recuperación real puede requerir pasos adicionales que aquí no se cubren. Para obtener ayuda, escriba a liu.maclean@gmail.com.
Escenario de recuperación 4: Recuperar filas eliminadas con DELETE FROM TABLE
Un desarrollador de la empresa D ejecutó un script para borrar datos en el entorno de pruebas, pero por error lo apuntó al entorno de producción (PROD DATABASE), borrando así todos los datos de una tabla.
En el escenario anterior, podemos usar DBRECOVER para recuperar las filas eliminadas.
Sin embargo, los usuarios deben realizar antes las siguientes operaciones para proteger en lo posible los datos frente a sobrescritura:
- Poner en modo READ ONLY el tablespace que contiene la tabla. El comando es: ALTER TABLESPACE {TABLESPACE_NAME} READ ONLY
- Parar la instancia de la base de datos: SHUTDOWN IMMEDIATE
Puede elegir cualquiera de las dos soluciones anteriores.
Reproducción del escenario:
SQL> select count(*) from pd.emp;
COUNT(*)
---------
114688
SQL> delete from pd.emp;
114688 rows deleted.
SQL> commit;
Commit complete.
SQL> alter system checkpoint;
System altered.
SQL> select count(*) from pd.emp;
COUNT(*)
---------
0
Antes de comenzar la recuperación, ponemos primero el tablespace en modo de solo lectura para proteger el entorno de recuperación:
SQL> select tablespace_name from dba_segments where owner='PD' and segment_name='EMP';
TABLESPACE_NAME
-----------------------------
DBRECOVER_TEST
SQL> alter tablespace DBRECOVER_TEST read only;
Tablespace altered.
Arranque DBRECOVER, escoja el modo diccionario y añada todos los datafiles disponibles:
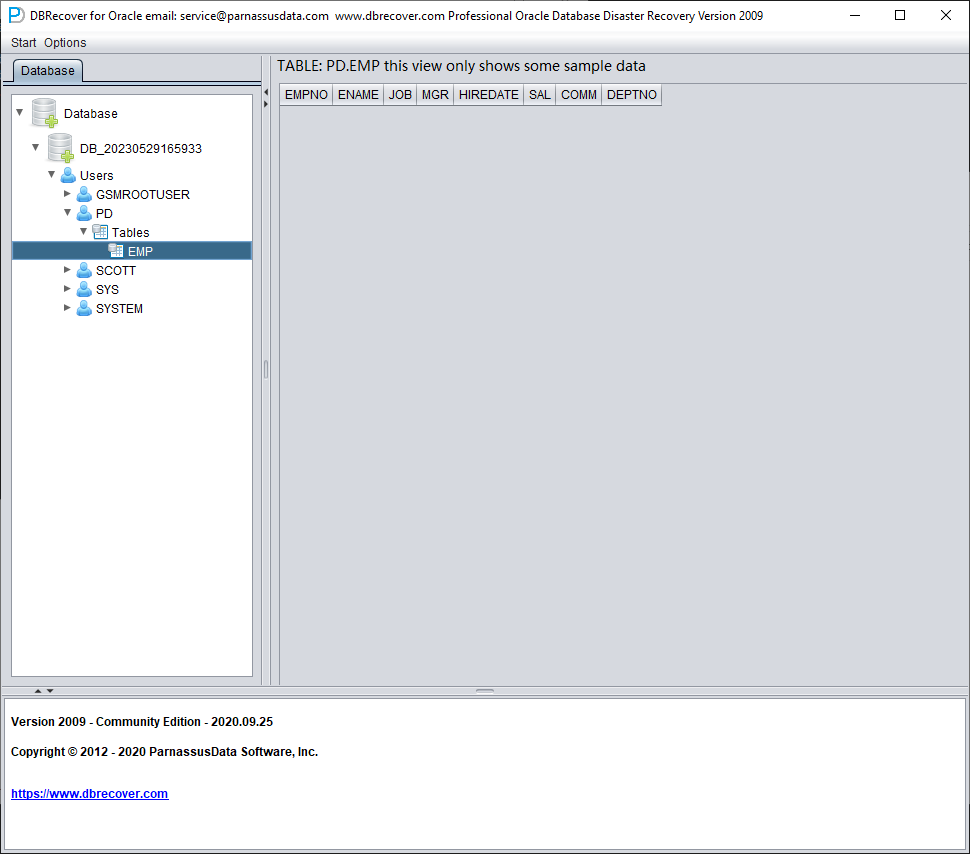
Los datos de la tabla de ejemplo parecen vacíos. Haga clic derecho sobre la tabla y elija Unload Deleted Data.
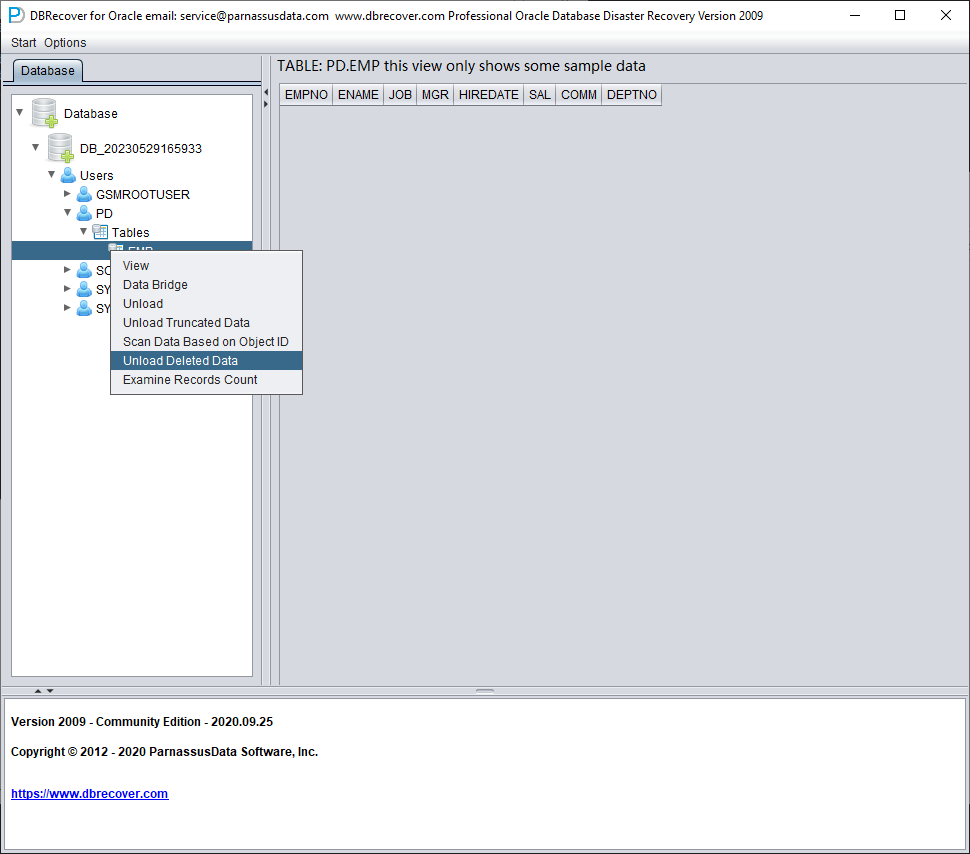
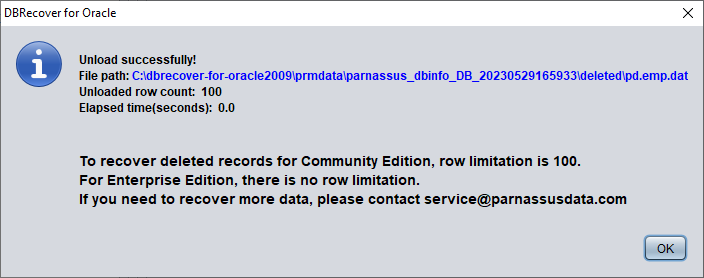
Sin una licencia empresarial válida, la función UNLOAD DELETED DATA está limitada a 100 filas por tabla.
Los datos recuperados se guardan en la ruta indicada en la ventana emergente:
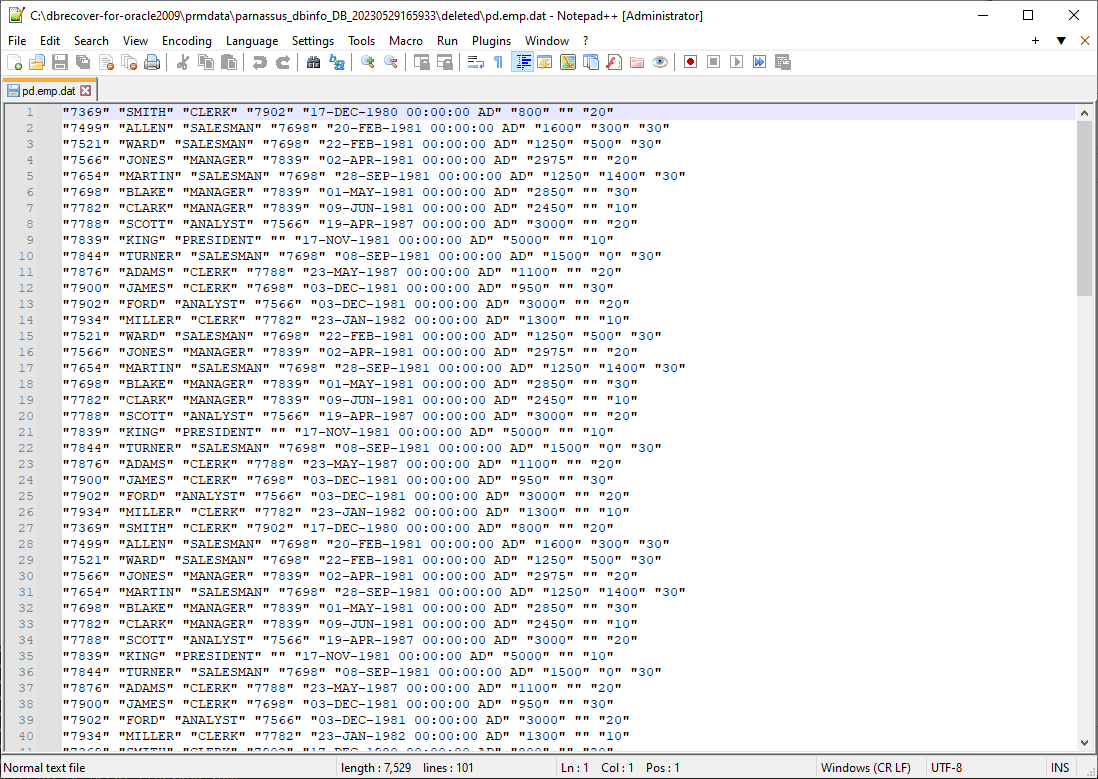
El usuario debe revisar el resultado de la recuperación y usar herramientas como SQLLDR o SQLDEVELOPER para insertar los datos de texto de nuevo en la base de datos.
Escenario de recuperación 5: Recuperación tras un TRUNCATE TABLE accidental
El personal de mantenimiento de aplicaciones de la empresa D confundió la base de datos de producción con la de pruebas y truncó por error todos los datos de una tabla. El DBA intentó recuperarlos, pero descubrió que el backup más reciente era inservible, por lo que era imposible restaurar los registros de esa tabla desde el backup. Llegado ese punto, el DBA decidió usar DBRECOVER para recuperar los datos truncados.
En este entorno todos los ficheros de la base de datos están disponibles y sanos. El usuario solo necesita cargar, en modo diccionario, los datafiles del tablespace SYSTEM y los del tablespace que contiene la tabla truncada. Por ejemplo:
SQL> select count(*) From pd.salgrade;
COUNT(*)
---------
655360
SQL> select tablespace_name from dba_segments where owner='PD' and segment_name='SALGRADE';
TABLESPACE_NAME
-----------------------------
APP01
SQL> truncate table pd.salgrade;
Table truncated.
SQL> alter system checkpoint;
System altered.
SQL> select count(*) from pd.salgrade;
COUNT(*)
---------
0
En este escenario de TRUNCATE no se utilizó almacenamiento ASM, por lo que basta con seleccionar «Dictionary Mode» (modo diccionario):
En la mayoría de los casos no hace falta modificar ningún parámetro:
Añada todos los datafiles disponibles:
Si abre USERS verá varios nombres de usuario. Si necesita recuperar una tabla del SCHEMA PD, abra PD y haga doble clic en el nombre de la tabla:
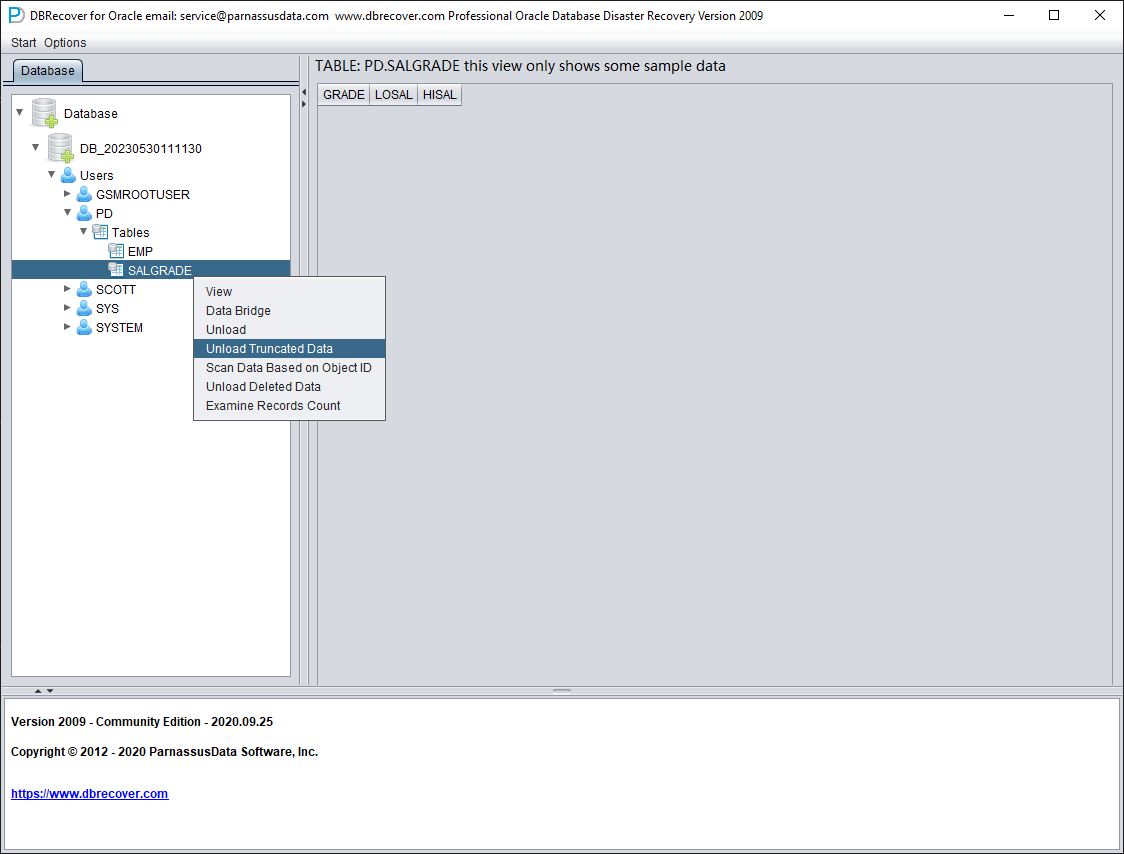
Como esta tabla ha sido truncada, el doble clic no muestra ningún dato. En ese momento, haga clic derecho sobre la tabla y elija «Unload truncated data»:
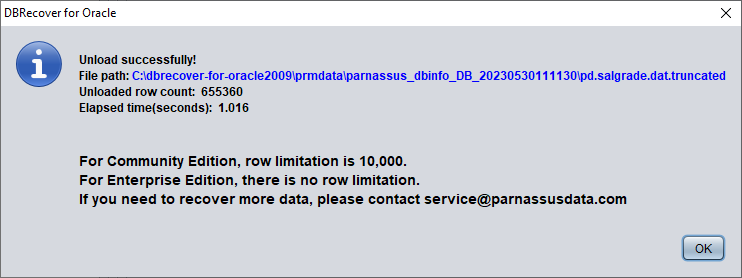
DBRECOVER intentará escanear el tablespace donde reside la tabla y extraer los datos truncados. Como se ve en la figura anterior, se extraen los 655 360 registros completos de la tabla truncada y se guardan en la ruta indicada.
El usuario puede revisar el fichero DAT para confirmar el resultado de la recuperación.
La clave para recuperar datos truncados es confirmar el DATA_OBJECT_ID que tenía la tabla antes del TRUNCATE. En este caso:
SQL> select object_id ,data_object_id from dba_objects where owner='PD' and object_name='SALGRADE';
OBJECT_ID DATA_OBJECT_ID
--------- --------------
76112 76113
Antes del TRUNCATE, el OBJECT_ID y el DATA_OBJECT_ID de la tabla eran ambos 76112. El TRUNCATE incrementó el DATA_OBJECT_ID a 76113, mientras que el OBJECT_ID se mantuvo igual.
Así que aquí el DATA_OBJECT_ID original es 76112. Pero si una tabla se ha truncado varias veces y necesita recuperar datos anteriores a un TRUNCATE previo, no puede limitarse a deducir el DATA_OBJECT_ID original a partir del OBJECT_ID actual.
Puede usar técnicas como flashback query, consulta del diccionario o minería de logs para determinar el DATA_OBJECT_ID; este es un ejemplo de flashback query:
SQL> select user# from sys.user$ where name='PD';
USER#
---------
106
SQL> select obj#,dataobj# from sys.obj$ as of timestamp systimestamp -1/24 where name='SALGRADE' and owner#=106;
OBJ# DATAOBJ#
--------- ----------
76112 76112
El DATAOBJ# original, es decir, el DATA_OBJECT_ID, se obtiene mediante la flashback query anterior.
A continuación, utilice la función Data Bridge para insertar los datos recuperados en la base de datos destino.
Crítico al transferir de vuelta a la base de datos de origen: si Data Bridge va a escribir en la misma base de datos de la que procedía la tabla truncada, el tablespace destino no debe ser el que contiene los datos truncados, y la tabla destino no debe ser la tabla de origen. Escribir en el tablespace de origen puede sobrescribir los extents residuales que DBRECOVER está intentando leer y dejar los datos irrecuperables. (Si transfiere a una base de datos totalmente distinta, esta precaución no aplica.)
Por eso, primero creamos un nuevo tablespace donde almacenar la tabla recuperada:
SQL> create tablespace pd_recover_data datafile size 600M;
Tablespace created.
Cree la información de conexión necesaria; recuerde que el usuario de base de datos debe tener los permisos adecuados (se recomienda otorgar el rol DBA).
Tras una prueba satisfactoria, pulse SAVE para guardar.
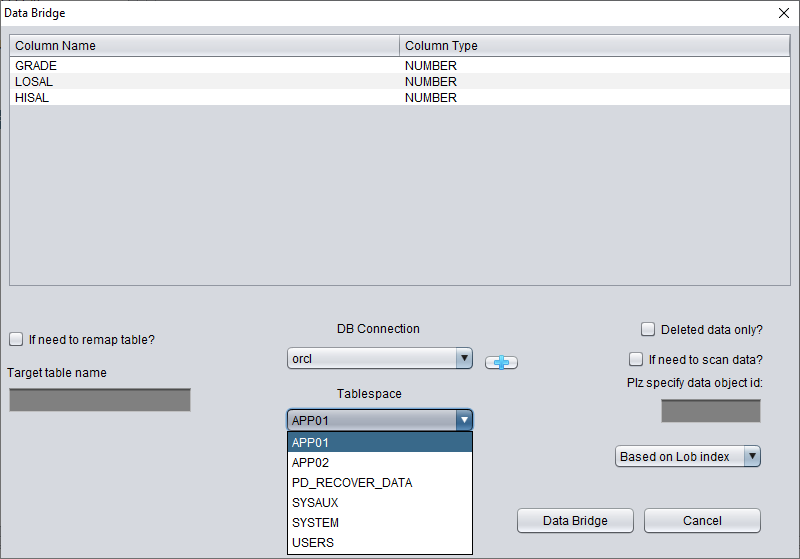
Arriba, seleccione el tablespace donde se almacenará la tabla recuperada del TRUNCATE.
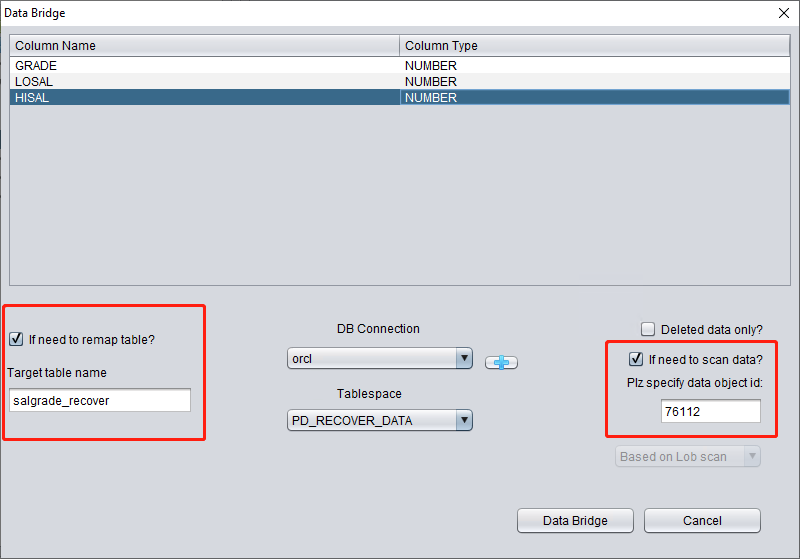
Aquí hay que marcar «if need to scan data» e introducir el DATA_OBJECT_ID original obtenido antes. De este modo, DBRECOVER escaneará específicamente los datos asociados a ese ID.
A la vez, hay que marcar «if need to remap table» e indicar un nuevo nombre de tabla, para que los datos se inserten en la tabla nueva (sobre el nuevo tablespace) y se excluya cualquier posibilidad de sobrescritura.
Nota:
- Si la tabla con ese nombre ya existe en la instancia destino, DBRECOVER no la recreará; simplemente insertará los datos de recuperación necesarios sobre la tabla existente. Como la tabla ya está creada, el tablespace indicado no surtirá efecto.
- Si la tabla con ese nombre no existe en el SCHEMA destino, DBRECOVER intentará crear una tabla sobre el tablespace especificado e insertar los datos de recuperación.
Una vez completados los pasos anteriores, pulse el botón Data Bridge.
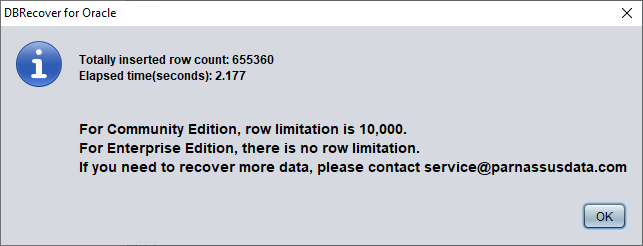
Confirme el número de filas recuperadas:
SQL> select count(*) from pd.salgrade_recover;
COUNT(*)
---------
655360
El principio básico del TRUNCATE es que, al producirse, ORACLE solo actualiza el Data Object ID de la tabla en el diccionario de datos y en la Segment Header; la parte real de datos en los bloques no se modifica. Como el DATA_OBJECT_ID del diccionario y de la Segment Header ya no coincide con el de los bloques de datos posteriores, el proceso servidor de ORACLE deja de leer los datos truncados al recorrer la tabla completa, aunque en realidad todavía no se hayan sobrescrito. Por eso DBRECOVER puede recuperar esos datos accediendo a los Data Extents que aún no se han modificado ni sobrescrito.
Escenario de recuperación 6: Recuperación tras un DROP TABLE accidental
Los desarrolladores de la aplicación de la empresa D droppearon una tabla central de la aplicación sin tener copias de seguridad. En esta situación, se puede usar DBRECOVER para recuperar la mayor parte de los datos de la tabla droppeada. A partir de 10g existe la papelera de reciclaje (recycle bin), que se puede consultar primero mediante la vista DBA_RECYCLEBIN para comprobar si la tabla está en ella. Si lo está, conviene primero hacer un flashback a un instante anterior al drop a través del recycle bin. Si no está en la papelera, use DBRECOVER inmediatamente para recuperarla.
De manera similar a la recuperación tras un TRUNCATE, para recuperar una tabla droppeada hay que determinar el DATA_OBJECT_ID original.
El proceso de recuperación, en líneas generales, es el siguiente:
- Primero, ponga en modo de solo lectura el tablespace donde residía la tabla droppeada con
ALTER TABLESPACE {TABLESPACE_NAME} READ ONLY, o copie inmediatamente todos los datafiles del tablespace.
- Localice el DATA_OBJECT_ID de la tabla droppeada consultando el diccionario de datos o usando LOGMINER.
- Arranque DBRECOVER en modo sin diccionario (NON-DICT), añada todos los datafiles del tablespace donde residía la tabla droppeada y, después, SCAN DATABASE + SCAN TABLE from Extent MAP.
- Localice la tabla correspondiente en el árbol de objetos expandido a través de su DATA_OBJECT_ID e insértela de vuelta en la base de datos de origen mediante Data Bridge.
Con LogMiner puede recuperar un DATA_OBJECT_ID aproximado. Un script de muestra:
EXECUTE DBMS_LOGMNR.ADD_LOGFILE( LOGFILENAME => '/oracle/logs/log1.f', OPTIONS => DBMS_LOGMNR.NEW);
EXECUTE DBMS_LOGMNR.ADD_LOGFILE( LOGFILENAME => '/oracle/logs/log2.f', OPTIONS => DBMS_LOGMNR.ADDFILE);
Execute DBMS_LOGMNR.START_LOGMNR(DBMS_LOGMNR.DICT_FROM_ONLINE_CATALOG+DBMS_LOGMNR.COMMITTED_DATA_ONLY);
SELECT * FROM V$LOGMNR_CONTENTS ;
EXECUTE DBMS_LOGMNR.END_LOGMNR;
También puede intentar extraer el DATA_OBJECT_ID minando los datos de AWR:
-- Query 1: compare DBA_HIST_SQL_PLAN / GV$SQL_PLAN against OBJ$
Select * from
(select object_name,object# from DBA_HIST_SQL_PLAN
UNION select object_name,object# from GV$SQL_PLAN) V1 where V1.OBJECT# IS
NOT NULL minus select name,obj# from sys.obj$;
-- Query 2: compare WRH$_SEG_STAT_OBJ against OBJ$
select obj#,dataobj#, object_name from WRH$_SEG_STAT_OBJ where object_name
not in (select name from sys.obJ$) order by object_name desc;
-- Query 3: compare DBA_HIST_ACTIVE_SESS_HISTORY against OBJ$
SELECT tab1.SQL_ID,
current_obj#,
tab2.sql_text
FROM DBA_HIST_ACTIVE_SESS_HISTORY tab1,
dba_hist_sqltext tab2
WHERE tab1.current_obj# NOT IN
(SELECT obj# FROM sys.obj$
)
AND current_obj#!=-1
AND tab1.sql_id =tab2.sql_id(+);
// Las tres consultas anteriores comparan los datos de AWR con la tabla base del diccionario OBJ$ para localizar la tabla droppeada.
Veámoslo en la práctica:
SQL> create table dropit as select * from dba_objects;
Table created.
SQL> select count(*) from pd.dropit;
COUNT(*)
---------
73095
SQL> select tablespace_name from dba_segments where owner='PD' and segment_name='DROPIT';
TABLESPACE_NAME
-----------------------------
USERS
SQL> select object_id ,data_object_id from dba_objects where owner='PD' and object_name='DROPIT';
OBJECT_ID DATA_OBJECT_ID
--------- --------------
76116 76116
SQL> drop table dropit;
Table dropped.
SQL> alter system checkpoint;
System altered.
Arrancamos DBRECOVER en modo diccionario (DICTIONARY-MODE); aquí solo hace falta añadir SYSTEM01.DBF y el datafile del tablespace USERS donde residía la tabla:
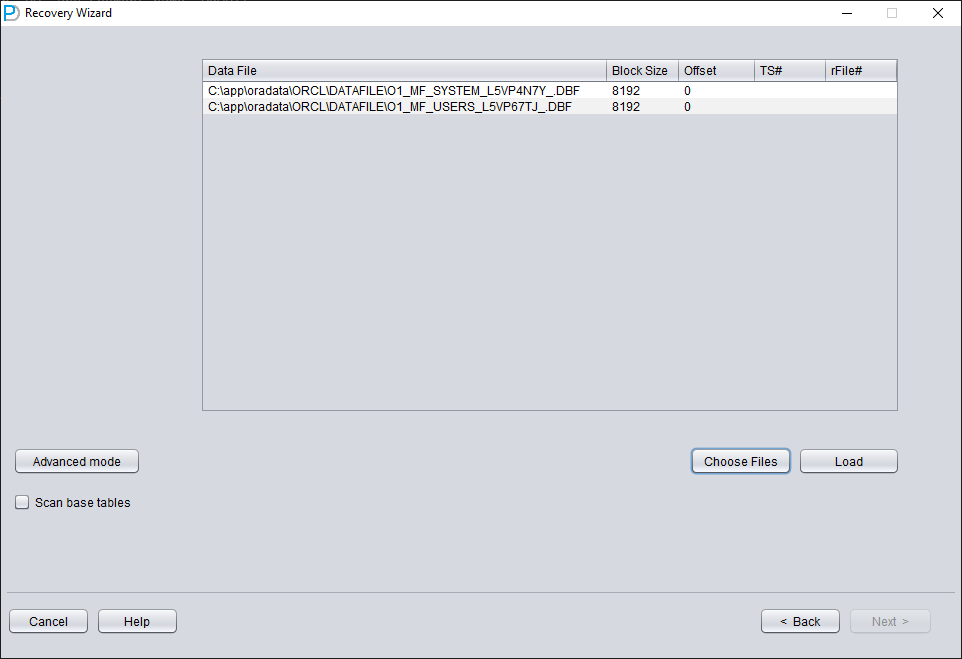
Una vez completada la carga, observamos que la tabla que queremos recuperar no aparece bajo el SCHEMA PD, lo cual es normal.
Seleccione el nodo de la base de datos y, con el botón derecho, elija SCAN Data.
A continuación aparecerá un nodo EXTENTS; busque el nodo OBJ76116:
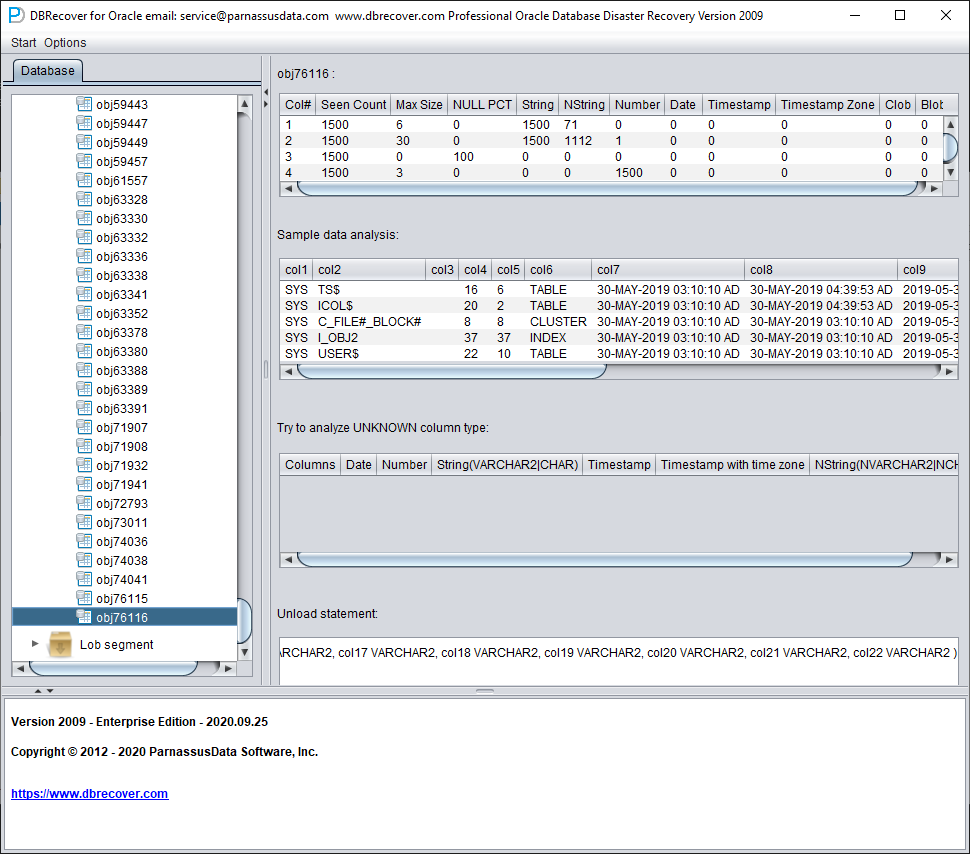
Después podemos usar la función Data Bridge para insertarla de vuelta en la base de datos de origen.
Escenario de recuperación 7: Recuperación tras un DROP TABLESPACE accidental
En la empresa D, un empleado tenía que eliminar un tablespace que ya no se usaba mediante una operación DROP TABLESPACE INCLUDING CONTENTS. Sin embargo, tras el DROP TABLESPACE, el departamento de desarrollo informó de que en ese tablespace había datos importantes de un SCHEMA. Ahora el tablespace está droppeado y no hay backups.
En esta situación, podemos usar el modo sin diccionario de DBRECOVER para extraer datos de todos los datafiles del tablespace droppeado. Con este método se puede recuperar la mayor parte de los datos. Sin embargo, al ser modo sin diccionario, las tablas recuperadas hay que asociarlas una a una con las tablas reales de la aplicación. Normalmente es necesario que intervenga el personal de desarrollo y mantenimiento de la aplicación para identificar manualmente qué datos pertenecen a qué tabla. Como la operación DROP TABLESPACE modifica el diccionario de datos y elimina los objetos del tablespace correspondiente en OBJ$, no podemos obtener desde OBJ$ la correspondencia entre DATA_OBJECT_ID y OBJECT_NAME. En este caso, podemos aplicar el método descrito en el escenario de DROP TABLE para recuperar el mayor número posible de correspondencias entre DATA_OBJECT_ID y OBJECT_NAME.
El proceso general es el siguiente:
Si durante el DROP TABLESPACE también se borraron físicamente los datafiles, hay que restaurarlos primero. Se puede intentar con software de recuperación a nivel de sistema de ficheros, o utilizar PRMSCAN para escanear y reorganizar los datafiles a nivel de bloque Oracle.
PRMSCAN es una herramienta de escaneo y fusión de fragmentos de bloques Oracle, adecuada para los siguientes escenarios:
- Borrado manual accidental de datafiles en el sistema de ficheros (cualquier sistema de ficheros: NTFS, FAT, EXT, UFS, JFS, etc.) o en ASM.
- El sistema de ficheros está dañado y el datafile ha quedado truncado a cero bytes.
- El sistema de ficheros está dañado y no se puede hacer MOUNT.
- Los metadatos del almacenamiento ASM están dañados y el diskgroup no puede hacer mount.
- El LV o PV del sistema de ficheros o de ASM está dañado físicamente o se ha perdido.
- En estos escenarios, prmscan puede escanear directamente los bloques Oracle residuales que no han sido sobrescritos en el PV o LV del sistema de ficheros o de ASM, fusionarlos y reorganizarlos para conseguir recuperar los datos.
PRMSCAN está desarrollado en JAVA y se puede ejecutar en todos los sistemas operativos que soporten JDK 1.6 o posterior, incluidos Windows, Linux, Solaris, AIX y HP-UX.
Este producto no está disponible actualmente para venta directa; puede ponerse en contacto con nosotros para que le prestemos los servicios de recuperación.
En el ejemplo siguiente, /dev/sdb1 es una partición ext4 que aloja un conjunto de datafiles de Oracle. El sistema de ficheros ext4 está dañado y SDB1 ya no se puede montar, por lo que la base de datos Oracle también queda inutilizable.
Aquí utilizamos la función de escaneo y fusión de bloques Oracle de prmscan para reorganizar directamente los datafiles desde el sistema de ficheros dañado.
Escanee el disco completo
[oracle@dbdao01 ~]$ java -jar PRMScan.jar –scan /dev/sdb1 –guess 8k
La opción --scan indica que se debe escanear el dispositivo /dev/sdb1 y fijar el blocksize de Oracle a 8k.
[oracle@dbdao01 ~]$ java -jar PRMScan.jar --outputsh ./8kfull.txtLa opción --outputsh genera un fichero SHELL capaz de fusionar la información escaneada; en este caso, 8kfull.txt.
[oracle@dbdao01 ~]$ sh 8kfull.txtAl ejecutar 8kfull.txt se generan en el directorio actual todos los datafiles que se deben fusionar.
Por ejemplo:
[oracle@dbdao01 ~]$ ls -ll PD*
rw-r–r– 1 oracle oinstall 295428096 Jul 28 00:37 PD_DBF1.dbf
rw-r–r– 1 oracle oinstall 83427328 Jul 28 00:37 PD_DBF2.dbf
rw-r–r– 1 oracle oinstall 220266496 Jul 28 00:37 PD_DBF3.dbf
rw-r–r– 1 oracle oinstall 1324482560 Jul 28 00:38 PD_DBF4.dbf
Si los datafiles no se han borrado físicamente, se pueden añadir directamente a DBRECOVER y escanear sus datos en NON-DICTIONARY MODE.
Los pasos posteriores pueden seguir el procedimiento descrito antes para DROP TABLE; la diferencia es que el objeto de recuperación de un DROP TABLESPACE serán muchas tablas en lugar de una sola.